Mar 5, 2015
Yesterday TechCrunch reported that Twitter now seems to be requiring SMS validation from new accounts registered over Tor. Though this might be effective for rate-limiting registration of abusive/spammy accounts, sometimes actual people use Twitter over Tor because anonymity is a prerequisite to free speech and circumventing information barriers imposed by oppressive governments. These users might not want to link their telco-sanctioned identity with their Twitter account, hence why they’re using Tor in the first place.
What are services like Twitter to do, then? I thought of one simple solution that borrows a popular idea from anonymous e-cash systems.
In a 1983 paper, cryptographer David Chaum introduced the concept of blind signatures. A blind signature is a cryptographic signature in which the signer can’t see the content of the message that she’s signing. So if Bob wants Alice to sign the message “Bob is great” without her knowing, he first “blinds” the message using a random factor that is unknown to her and gives Alice the blinded message to sign. When he unblinds her signed message by removing the blinding factor, the original message “Bob is great” also has a valid signature from Alice!
This may seem weird and magical, but blinded signatures are actually possible using the familiar RSA signature scheme. The proof is straightforward and on Wikipedia. Basically, since RSA signatures are just modulo’d exponentiation of some message M to a secret exponent d, when you create a signature over a blinded message M’ = M*r^e (where r is the blinding factor and e is the public exponent), you also create a valid signature over M thanks to the distributive property of exponentiation over multiplication.
Given the existence of blind signature schemes, Twitter can do something like the following to rate-limit Tor accounts without deanonymizing them:
- Say that @bob is an existing Twitter user who would like to make an anonymous account over Tor, which we’ll call @notbob. He computes T = H(notbob) * r^e mod N, where H is a hash function, r is a random number that Bob chooses, and {e,N} is the public part of an Identity Provider’s RSA keypair (defined in step 2).
- Bob sends T to an identity provider. This could be Twitter itself, or any service like Google, Identica, Facebook, LinkedIn, Keybase, etc. as long as it can check that Bob is probably a real person via SMS verification or a reputation-based algorithm. If Bob seems real enough, the Identity Provider sends him S_ig(T) = T^d mod N = H(notbob)^d * r mod N_, where d is the private part of the Identity Provider’s RSA keypair.
- Bob divides Sig(T) by r to get Sig(H(notbob)), AKA his Identity Provider’s signature over the hash of his desired anonymous username.
- Bob opens up Tor browser and goes to register @notbob. In the registration form, he sends Sig(H(notbob)). Twitter can then verify the Identity Provider’s signature over ‘notbob’ and only accept @notbob’s account registration if verification is successful!
It seems to me that this achieves some nice properties.
- Every anonymous account is transitively validated via SMS or reputation.
- Ignoring traffic analysis (admittedly a big thing to ignore), anonymous accounts and the actual identities or phone numbers used to validate them are unlinkable.
Thoughts? I’d bet that someone has thought of this use case before but I couldn’t find any references on the Internet.
Feb 16, 2015

that could have been us, 2015
Oil pastels, lipstick, eyeliner, cold medicine, and ballpoint pen on canvas.
i painted this while standing in my bathroom on valentine’s day’s night, unable to sleep and grotesquely feeling the weight of the oncoming dawn. it was my first time drawing on canvas.
as i worked, i kept thinking about all these people passing to and from doomed relationships, that feeling of being stupidly and everlastingly perched on the brink between hope and mutilation. that’s more or less what this is about.
Dec 31, 2014
I remember quite clearly sitting in Scott Aaronson’s computability and complexity theory course at MIT in 2011. I was a 19 year-old physics major back then, so Scott’s class was mostly new and fascinating.
One spring day, Scott was at the chalkboard delightedly introducing the concept of time complexity classes to us, with the same delight he used when introducing most abstract constructs. He said that you could categorize algorithms into time complexity classes based on the amount of time they take to run as a function of the input length. For instance, you could prove that certain decision problems couldn’t be solved by a deterministic Turing machine in polynomial time. I raised my hand.
“Yes?”
“But time is reference-frame dependent! What if you ran the deterministic Turing machine on earth while you yourself were on a rocket going at relativistic speeds?”
Scott’s eyes lit up. “Aha!” he said, without pause. “Suppose you traveled faster as the input length increased, so from your perspective, a problem in EXP is decidable in polynomial time. However you would be using more and more energy to propel your spaceship. So there is necessarily a tradeoff in the resources needed to solve the problem.”
In retrospect, this was pretty characteristic of why I liked the class so much. Scott didn’t give the easy and useless answer, which would have been that *by our definition* all running times are measured in a fixed inertial reference frame. Instead he reminds us that we, as humans, ultimately care about the totality of resources needed to solve a problem. Time complexity analysis is just one step toward grasping at how hard, how expensive, how painful something really is; mired as we may be in mathematical formalism, the reality of our dying planet and unpaid bills stays within sight when Scott lectures.
All this came to mind when I read Scott’s now-infamous blog comment about growing up as a shy, self-proclaimed and self-hating male nerd; followed by the much-cited response from journalist Laurie Penny about growing up as a shy, self-proclaimed and self-hating female nerd; followed by Scott’s latest blog post clarifying what he believes about feminism and the plight of shy nerdy people anguished by sexual frustration. What suprised me about the latter was that Scott went so far as to write:
“How to help all the young male nerds I meet who suffer from this problem, in a way that passes feminist muster, and that triggers the world’s sympathy rather than outrage, is a problem that interests me as much as P vs. NP, and right now that seems about equally hard.”
(“As much as P vs NP”?! Remember that Scott once bet his house on the invalidity of a paper claiming to prove P != NP, cf. http://www.scottaaronson.com/blog/?p=456.)
Sometimes I think that the obvious step towards solving the problem Scott mentions is for the frustrated person to politely and non-expectantly inform the other person of his/her desires. In an ideal world, they would then discuss them until reaching an amicable resolution, at which point they can return to platonically multiplying tensors or whatever.
But I suppose part of the definition of shy is the fear of exposing yourself to untrusted parties, for which they can reject you, humiliate you, and otherwise destroy that which you value or at least begrudgingly tolerate. Sadly, the shyness of analytical minds seems justified, because pretty much nobody has worked out how to communicate rejection without passing unfair judgement or otherwise patterning poisonous behavior. There is an art to divulging hidden feelings, an art to giving rejection, an art to handling sadness graciously, and an art to growing friendships from tenuous beginnings. None of these are taught to adolescent humans. Instead, we learn to hide ourselves and shame others.
I feel unprepared to write anything resembling a guide on how to do this, having recoiled from human contact for most of my life thanks to shyness, but I think it’s well worth some human brain cycles. Here’s hoping to live in a culture of rejection-positivity.
Dec 10, 2014
Yesterday the W3C Technical Architecture Group published a new finding titled, “The Web and Encryption.” In it, they conclude:
“. . . the Web platform should be designed to actively prefer secure origins — typically, by encouraging use of HTTPS URLs instead of HTTP ones. Furthermore, the end-to-end nature of TLS encryption must not be compromised on the Web, in order to preserve this trust.”
To many HTTPS Everywhere users like myself, this seemed a decade or so beyond self-evident. So I was surprised to see a flurry of objections appear on the public mailing list thread discussing the TAG findings.
It seems bizarre to me that security-minded web developers are spending so much effort hardening the web platform by designing and implementing standards like CSP Level 2, WebCrypto, HTTP Public Key Pinning, and Subresource Integrity, while others are still debating whether requiring the bare minimum security guarantee on the web is a good thing. While some sites are preventing any javascript from running on their page unless it’s been whitelisted, other sites can’t even promise that any user will ever visit a page that hasn’t been tampered with.
small consolation: the second one has more downloads
Obviously we shouldn’t ignore arguments for a plaintext-permissive web; they’re statistically useful as indicators of misconceptions about HTTPS and sometimes also as indicators of real friction that website operators face. What can we learn?
Here’s some of my observations and responses to common anti-HTTPS points (as someone who lurks on standards mailing lists and often pokes website operators to deploy HTTPS, both professionally and recreationally):
- “HTTPS is expensive and hard to set up.” This is objectively getting better. Cloudflare offers automatic free SSL to their CDN customers, and SSLMate lets you get a cert for $10 using the command line. In the near future, the LetsEncrypt cert authority will offer free certificates, deployed and managed using a nifty new protocol called ACME that makes the entire process take <30 seconds.
- “There is no value in using HTTPS for data that is, by nature, public (such as news articles).” This misses the point that aggregated browsing patterns, even for only public sites, can reveal a lot of private information about a person. If it weren’t, advertisers wouldn’t use third-party tracking beacons. QED.
- “TLS is slow.” Chris Palmer thought you would ask this and gave an excellent presentation explaining why not. tl;dr: TLS is usually not noticeably slower, but if it is, chances are that you can optimize away the difference (warning: the previous link is highly well-written and may cause you to become convinced that TLS is not slow).
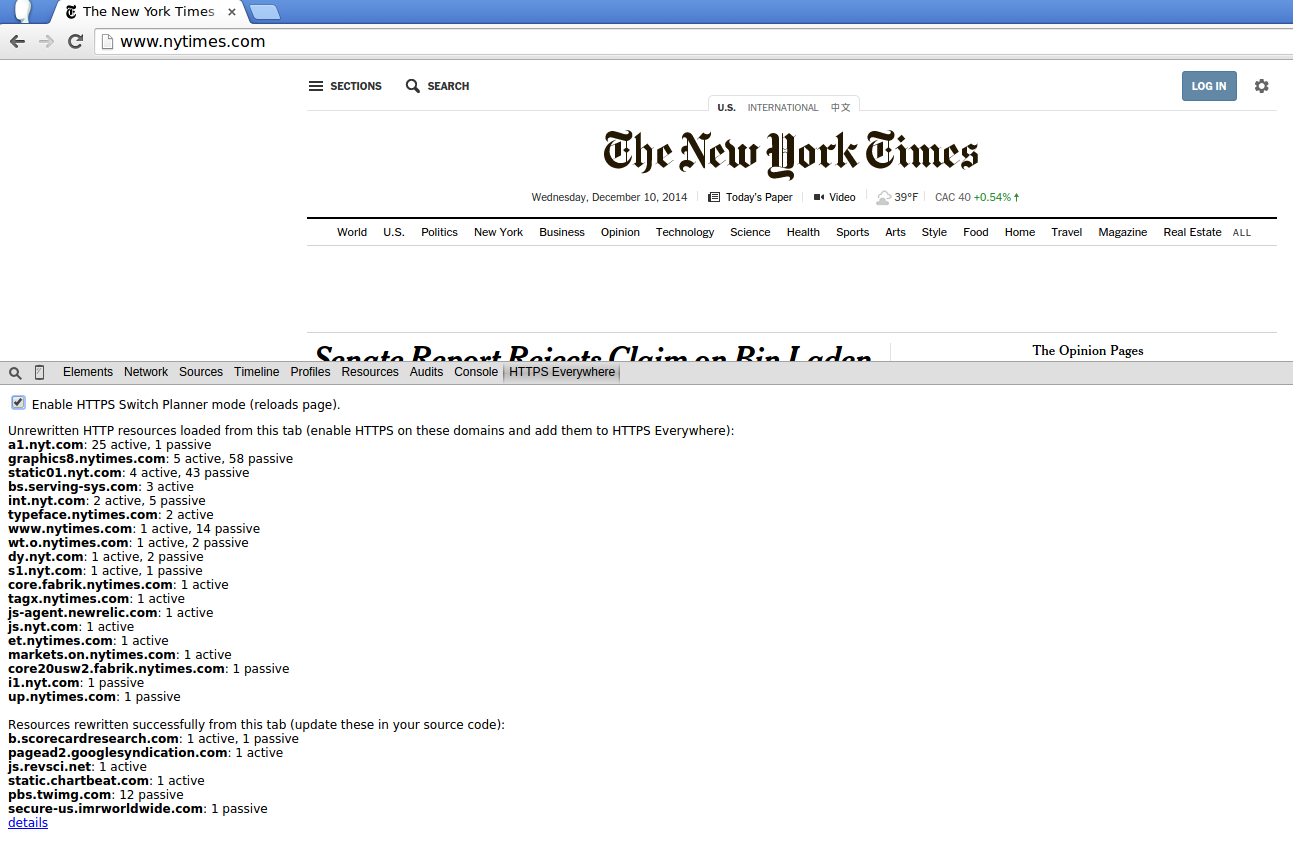
- “HTTPS breaks feature X.” This is something I’m intimately familar with, since most bug reports in HTTPS Everywhere (which I used to maintain) were caused by the extension switching a site to HTTPS and suddenly breaking some feature. Mixed content blocking was the biggest culprit, but there were also cases where CORS stopped working because the header whitelisted the HTTP site but not the HTTPS one. (I also expected some “features” to break because HTTPS sites don’t leak referer to HTTP ones, but surprisingly this never happened.) Luckily if you’re using HTTPS Everywhere in Chrome, there is a panel in the developer console that helps you detect and fix mixed content on websites (shown below). Setting the CSP report-only header to report non-HTTPS subresources is similarly useful but doesn’t tell you which resources can be rewritten.
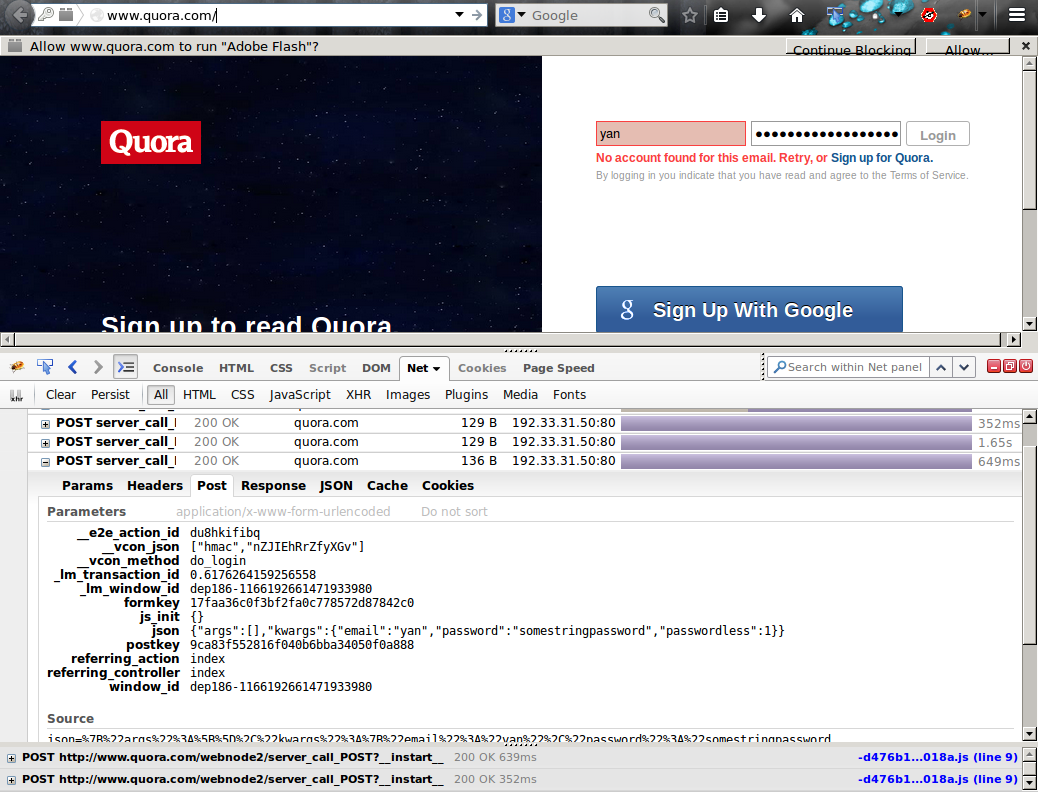
- “HTTPS gives users a false sense of security.” This comes up surprisingly often from various angles. Some people frame this as, “The CA system isn’t trustworthy and is breakable by every government,” while others say, “Even with HTTPS, you leak DNS lookups and valuable metadata,” and others say, “But many site certificates are managed by the CDN, not the site the user thinks they’re visiting securely.” The baseline counterargument to all of these is that encryption, even encryption that is theoretically breakable by some people, is better than no encryption, which doesn’t need to be broken by anyone. CA trustworthiness in particular is getting better with the implementation of certificate transparency and key pinning in browsers; let’s hope that we solve DNSSEC someday too. Also, regardless of whether HTTPS gives people a false sense of security, HTTP almost certainly gives the average person a false sense of security; otherwise, why would anyone submit their Quora password in plaintext?
In summary, it’s very encouraging to see the TAG expressing support for a ubiquitous transit encryption on the web (someday), but from the resulting discussion, it’s clear that developers still need to be convinced that HTTPS is efficient, reliable, affordable, and worthwhile. I think the TAG has a clear path forward here: separate the overgrown anti-HTTPS mythology from the actual measurable obstacles to HTTPS deployment, and encourage standards that fix real problems that developers and implementers have when transitioning to HTTPS. ACME, HPKP, Certificate Transparency, and especially requiring minimum security standards for powerful new web platform features are good examples of work that motivates website operators to turn on HTTPS by lowering the cost and/or raising the benefits.
Aug 14, 2014
Yesterday, Prof. Matthew Green wrote a nice blog post about why PGP must die. Ignoring the UX design problem for now, his four main points were: (1) the keys themselves are too unwieldy, (2) key management is hard, (3) the protocol lacks forward secrecy, and (4) the crypto is archaic/non-sane by default.
Happily, (1) and (4) can be solved straightforwardly using more modern crypto primitives like Curve25519 and throwing away superfluous PGP key metadata that comes from options that are ignored 99.999999% of the time. Of course, we would then break backwards compatibility with PGP, so we might as well invent a protocol that has forward/future secrecy built-in via something like Trevor Perrin’s axolotl ratchet. Yay.
That still leaves (2) – the problem of how to determine which public key should be associated with an endpoint (email address, IM account, phone number, etc.). Some ways that people have tried to solve this in existing encrypted messaging schemes include:
- A central authority tells Alice, “This is Bob’s public key”, and Alice just goes ahead and starts using that key. iMessage does this, with Apple acting as the authority AFAICT. Key continuity may be enforced via pinning.
- Alice and Bob verify each others’ key fingerprints via an out-of-band “secure” channel – scanning QR codes when they meet in person, reading fingerprints to each other on the phone, romantically comparing short authentication strings, and so forth. This is used optionally in OTR and ZRTP to establish authenticated conversations.
- Alice tries to use a web of trust to obtain a certification chain to Bob’s key. Either she’s verified Bob’s key directly via #2 or there is some other trust path from her key to Bob’s, perhaps because they’ve both attended some “parties” where people don’t have fun at all. This is what people are supposed to do with PGP.
- Alice finds Bob’s key fingerprint on some public record that she trusts to be directly controlled by Bob, such as his Twitter profile, DNS entry for a domain that he owns, or a gist on his Github account. This is what Keybase.io does. (I only added this one after @gertvdijk pointed it out on Twitter, so thanks Gert.)
IMO, if we’re trying to improve email security for as many people as possible, the best solution minimizes the extent to which the authenticity of a conversation depends on user actions. Key management should be invisible to the average user, but it should still be auditable by paranoid folks. (Not just Paranoid! folks, haha.)
Out of the 3 options above, the only one in which users have to do zero work in order to have an authenticated conversation is #1. The downside is that Apple could do a targeted MITM attack on Alice’s conversation with Bob by handing her a key that Apple/NSA/etc. controls, and Alice would never know. (Then again, even if Alice verified Bob’s key out-of-band, Apple could still accomplish the same thing by pushing a malicious software update to Alice.)
Clearly, if we’re using a central authority to certify people’s keys, we need a way for anyone to check that the authority is not misbehaving and issuing fake keys for people. Luckily there is a scheme that is designed to do exactly this but for TLS certificates – Certificate Transparency.
How does Certificate Transparency work? The end result is that a client that enforces Certificate Transparency (CT) recognizes a certificate as valid** **if (1) the certificate has been signed by a recognized authority (which already happens in TLS) and (2) the certificate has been verifiably published in a public log. The latter can be accomplished through efficient mathematical proofs because the log is structured as a Merkle tree.
How would CT work for email? Say that I run a small mail service, yanmail.com, whose users would like to send encrypted emails to each other. In order to provide an environment for crypto operations that is more sandboxed and auditable than a regular webpage, I provide a YanMail browser extension. This extension includes (1) a PGP or post-PGP-asymmetric-encryption library, (2) a hardcoded signing key that belongs to me, and (3) a library that implements a Certificate Transparency auditor.
Now say that alice@yanmail.com wants to email bob@yanmail.com. Bob has already registered his public key with yanmail.com, perhaps by submitting it when he first made his account. Alice types in Bob’s address, and the YanMail server sends her (1) a public key that supposedly belongs to Bob, signed by the YanMail signing key, and (2) a CT log proof that Bob’s key is in the public CT log. Alice’s CT client verifies the log proof; if it passes, then Alice trusts Bob’s key to be authentic. (Real CT is more complicated than this, but I think I got the essential parts here.)
Now, if YanMail tries to deliver an NSA-controlled encryption key for Bob, Bob can at least theoretically check the CT log and know that he’s being attacked. Otherwise, if the fake key isn’t in the log, no other YanMail user would trust it. This is an incremental improvement over the iMessage key management situation: key certification trust is still centralized, but at least it’s auditable.
What if Alice and Bob want to send encrypted email to non-YanMail users? Perhaps the browser extension also hard-codes the signing keys for these mail providers, which are used to certify their users’ encryption keys. Or perhaps the mail providers’ signing keys are inserted into DNS with DANE+DNSSEC. Or perhaps the client just trusts any valid CA-certified signing key for the mail provider.
For now, with the release of Google End-to-End and Yahoo’s announcement to start supporting PGP as a first-class feature in Yahoo mail, CT for (post)-PGP seems promising as a way for users of these two large webmail services to send authenticated messages without having to deal with the pains of web-of-trust key management. Building better monitoring/auditing systems can be done incrementally once we get people to actually *use* end-to-end encryption.
Large caveat: CT doesn’t provide a solution for key revocation as I understand it – instead, in the TLS case, it still relies on CRL/OCSP. So if Bob’s PGP/post-PGP key is stolen by an attacker who colludes with the YanMail server, they can get Alice to send MITM-able messages to Bob encrypted with his stolen key unless there is some reliable revocation mechanism. Ex: Bob communicates out-of-band to Alice that his old key is revoked, and she adds the revoked key to a list of keys that her client never accepts.
Written on 8/14/14 from a hotel room in Manila, Philippines
_==============
_
Update (8/15/14):
Thanks for the responses so far via Twitter and otherwise. Unsurprisingly, I’m not the first to come up with this idea. Here are some reading materials related to CT for e2e communication:
Update (8/29/14):
Since I posted this, folks from Google presented a similar but more detailed proposal for E2E. There has been a nice discussion about it on the Modern Crypto list, in addition to the one in the comments section of the proposal.
** Update (7/18/15):**
I know it’s pretty silly to be updating this after a year, but it’d be a travesty to not mention CONIKS here.
Jul 21, 2014
4 years ago, I went to HOPE for the first time on a last-minute press pass from my college newspaper. Some relevant facts about the trip:
- I was 19 and had never been to a hacker con before.
- I didn’t identify as a hacker (or an activist).
- I was too shy to talk to anyone the entire time. Combined with the fact that I knew only a few people there, I was mostly off by myself.
- HOPE that year was the pinnacle of paranoia in probably the most paranoid period of my life. This was 2010, a few months after Chelsea Manning was arrested for leaking a trove of documents to WikiLeaks. Coincidentally, Chelsea Manning had visited my house in the autumn of 2009; this was cause enough for suspicion from certain groups and frequent questions from reporters once the WikiLeaks story broke. Julian Assange was scheduled to give the keynote at HOPE, so you can imagine the atmosphere that year.
- Overall it was a fun experience regardless.
This year I finally made it back to HOPE. Things were a little different than last time:
- I flew in from Europe instead of driving from Boston.
- I was representing EFF and Freedom of the Press Foundation, two organizations that were almost-universally loved by the attendees.
- I co-presented two talks in front of overflowing rooms of people and got lots of audience feedback.
- I didn’t have time to talk to all the people that I wanted to, much less all the people who were trying to ask me questions.
- Whereas last time I made it to several talks per day, this year I was working from 4 AM in the morning until whenever-I-had-to-give-a-presentation for the first 2/3rds of the conference, then running off to meetings or working shifts at the EFF/FPF booths. As a result, I made it to a total of 3 or 4 talks that weren’t mine. 🙁
- It was eerie to have contributed to a project that kept getting name-dropped during the conference by the likes of Daniel Ellsberg and Barton Gellman. Literally dozens of people approached me to say that they wanted to help out with SecureDrop or set up an instance. Wow!
Predictably, it was strange to be a very-minor celebrity at a conference where I’d previously felt like an outsider and deliberately tried to make myself invisible. 4 years ago, my experience in the last 4 days would have seemed impossible for a plethora of reasons: I wasn’t a good public speaker*, I had a lot of self-doubt that I could contribute anything to the event, I felt weird for not having the same interests and background as the vast majority of people at HOPE, I didn’t know much about computers, I didn’t think that I was working on anything interesting, etc.
*Public speaking workshops are immensely helpful here; so does taking an introductory voice acting class.
Despite the slowly-fading jetlag and piling exhaustion after a month of international travel, it felt nice to contribute back to a conference that had been an eye-opening experience to me the first time.
Many thanks to the following people for working on presentations with me, giving last-minute feedback, and/or letting me sleep in their room: Parker Higgins, Bill Budington, Garrett Robinson, Trevor Timm, Runa Sandvik, James Dolan, Kevin Gallagher, Noah Swartz. Also thanks for Oliver Day for appointing me CSO of his company even though I haven’t fixed the SSL cert for his website yet.

Photo by Scott J. O’Brien (@scottjobrien)
Jul 11, 2014
Say that you want to “securely” acquire an app called EncryptedYo for “securely” communicating with your friends. You go to the developer’s web site, which is HTTPS-only, and download a binary executable. Done!
Perhaps if you’re paranoid, you fetch the developer’s GPG key, make sure that there’s a valid trust path to it from your own key, verify the detached signature that they’ve posted for the binary, and check that the checksum in the signature is the same as that of the binary that you’ve downloaded before installing it.
This is good enough as long as the only things you’re worried about are MITM attacks on your network connection and compromise of the server hosting the software. It’s not good enough if you’re worried about any of the following:
- The developer getting a secret NSA order to insert a backdoor into the software.
- The developer intentionally making false claims about the security of the software.
- The developer’s build machine getting compromised with malware that injects backdoors during the packaging process (pre-signing) or even a malicious compiler.
All of the above are *Very Real Worries* (TM) that users should have when installing software. As a maintainer of a security-enhancing browser extension used by millions of people, I used to worry about the third one before HTTPS Everywhere had a deterministic build process (more on that below). If my personal laptop was compromised by a malicious version of zip that rewrote the static update-fetching URL in the HTTPS Everywhere source code before compressing and packaging it, literally millions of Firefox installations would be pwned within a few days if I didn’t somehow detect the attack before signing the package (which is basically impossible to do in general).
You might instinctively think that the scenarios above are at least *detectable* if the software is open source and has been well-audited, but that’s not really true. Ex:
- How do I know that some binary executable that I downloaded from https://coolbinaryexecutables.com actually corresponds to the well-audited, peer-reviewed source code posted at https://github.com/coolstuff/EncryptedYo.git?
- How do I know that the binary executable that I downloaded is the same as the one that everyone else downloaded? In other words, how can I be sure that it’s not my copy and *only* my copy that has a secret NSA backdoor?
So it looks like there’s a problem because we usually install software from opaque binaries or compressed archives that have no guarantee of actually corresponding to the published, version-controlled source code. You might try to solve this by cloning the EncryptedYo repo and building it yourself. You can even fetch it over Tor and/or compare your local git HEAD to someone else’s copy’s if you want a stronger guarantee against a targeted backdoor.
Unfortunately that’s too much to ask the average person to do *every single time* they need to update the software, especially if EncryptedYo’s target audience includes non-technical people (ex: Glenn Greenwald).
This is why post-Snowden software developers need to start working on new code packaging and installation mechanisms that preserve “software transparency,” a phrase perhaps first used in this context by Seth Schoen. Software transparency, unlike open source by itself, is a guarantee that the packages you’re installing or updating were created by building the published source code.
(Side note: Software transparency has open source code as a prerequisite, but a similar concept that I’ve been calling “binary transparency” can be applied to closed-source software as well. Binary transparency is a guarantee that the binary you’re downloading is the same as the one that everyone else is downloading, but not that the binary is non-compromised. One way to get this is to compare the checksum of your downloaded binary gainst an out-of-band append-only cryptographically-verifiable log (phew) of binary checksums, similar to what Ben Laurie proposed in this blog post.)
In the last year, software transparency has finally started to become a front-and-center goal of some projects. Organizations like Mozilla and EFF are beginning to work on fully-reproducible build processes so that other people can independently build their software packages from source and make sure that their checksums are the same as the ones posted on mozilla.org or eff.org. Mike Perry of the Tor Project has written about the painstaking, years-long process that it took to compile the Tor Browser Bundle deterministically inside a VM, but for many other software projects, the path to a reproducible build is as simple as normalizing timestamps in zip.
Of course, a reproducible build proccess doesn’t by itself impact the average user, who is unlikely to try to replicate the build process for Firefox for Android before installing it on their phone. But at least it means that if Mozilla started posting backdoored binaries because their build machine was compromised, some members of their open source development community could in theory detect the attack after-the-fact and raise suspicions. That’s more than we could do before.
IMO, every reasonably-paranoid software developer should be trying to adopt an independently reproducible build process. Gitian is a good place to start.
(Part 2 of this series, which I haven’t written yet, is probably going to be about implementing software transparency in a way that protects end users before they get pwned, which nobody is doing much of yet AFAIK. In particular, it would be nice to start discussing ways to enforce software transparency for resources loaded in a browser, in hopes that this will bring either some clarity or more shouting to the debate about whether in-browser crypto apps are a good idea.)
Jun 25, 2014
This was my favorite part of my interview with The Setup:
What would be your dream setup?
Let’s start with the easy ones. I would like (1) an e-book reader that has the portability and battery life of a Kindle, runs free software out-of-the-box, and doesn’t support DRM; (2) an open-source maps application for Android/CyanogenMod that can provide biking and public transit directions for any city that I happen to be in; and (3) a usable open-source password manager that syncs to mobile devices, integrates with browsers, and meets some set of minimum security requirements. (I’ll work on the latter if someone else does the first two.)
Slightly more ambitious: every device should come with root access for the user if they want it. Going down the stack, it would be nice if all computing devices by default ran a free BIOS and other free firmware on top of easily-modifiable, open hardware.
Respecting the autonomy of users by allowing them to understand and modify their devices is crucial for creating widespread technical literacy and, subsequently, a world in which ordinary people can detect when their rights are being threatened by technology providers and governments. I have a crazy dream that, someday, ordinary families will sit down at their kitchen tables to install software updates together and read the change logs aloud over breakfast.
Shooting for the stars now: let’s design computers so that software engineering doesn’t force us to occupy constrained, mostly-immobile positions in florescent-lit rooms for 8+ hours every day. I’d like to code and go backpacking at the same time.
Jun 16, 2014
Every week, answer “yes” to one question that you would instinctively say no to.
Don’t spend money or sleep in a real bed for as long as possible.
Buy a pound of the ugliest paint that you can find.
Keep a journal of thoughts you avoid.
Block port 80 for a day.
Be kind at random.
Jun 12, 2014
Hi there. Have a funny picture:
Today, I was briefly worried by the observation that mainstream media takes 24-36 hours to start freaking out about over half of web encryption being fundamentally broken, compared to 2-3 hours for an XSS bug in a Twitter client that causes self-retweeting tweets and unexpected rickrolls and such. Then I remembered that most Americans watch TV for like 4+ hours per day. (XSS is arguably the most telegenic class of software QA issues.)
I don’t use TweetDeck, but I managed to download the much-XSSed Chrome extension today shortly before it was fixed. I unminified the content script (the one that modifies page content on the client side, therefore probably causing whatever XSS was there) and took a diff with the patched version (3.7.2) after it came out. Pastebin here.
A couple things stood out:
- Some people on Twitter (or maybe the people who XSSed their accounts, haha) implied that the XSS was due to Twitter not escaping user input. This seems false, because I can see safely-escaped HTML in HTTP responses from Twitter in my browser. This is sort of interesting, because it implies that the TweetDeck client is somehow unescaping escaped HTML.
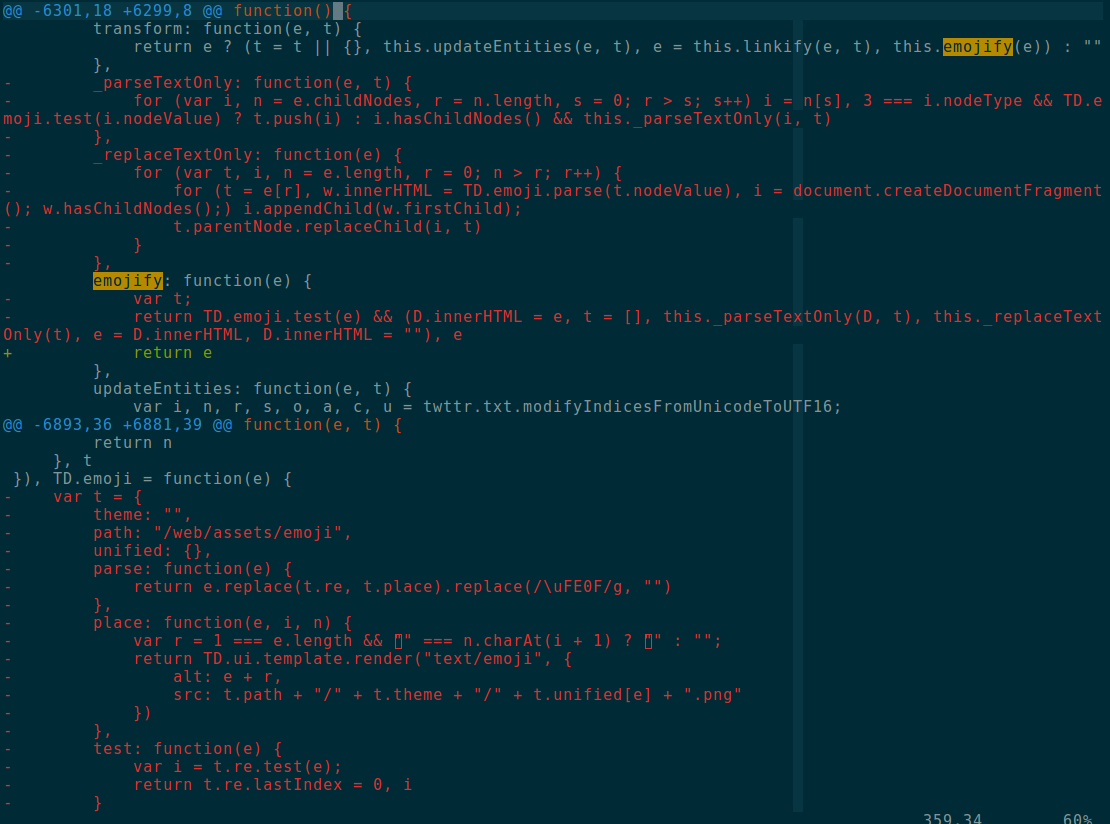
- The bulk of the not-very-well-obfuscated-but-still-hard-to-read diff between 3.7.1 and 3.7.2 was ripping out emoji “parsing” code. “parsing” is in quotes because TweetDeck processes tweets and tries to replace all Emoji characters with HTML image tags before showing them to you.
3.7.2, quite happily, replaced the “emojify” function with the identity function (pictured above).
After staring at the diff some more, I sort-of figured out what was going on. TweetDeck runs a utility function on the DOM that extracts every text node, t, that contains an emoji character. Then for each text node t, it does the equivalent of:
someDiv.innerHTML = this.emoji.parse(t.nodeValue);
var i = document.createDocumentFragment();
while (someDiv.hasChildNodes()) {
i.appendChild(someDiv.firstChild);
}
t.parentNode.replaceChild(i, t);
where emoji.parse is the function that replaces emoji with HTML img tags.
“innerHTML is evil!!” one might say. This is true, but not the sole problem in this case because Chrome and Firefox will not automatically execute js inside text in the tweet disappears, because now the browser sees it as a script element instead of as text.
It’s not hard to imagine ways this bug could have been created. UX designer says, “We need to add better emoji rendering before the release next week.” Another developer decides that emoji need to be converted into images and copies-and-modifies some code from the same script that renders “@” mentions in text as HTML links but forgets to re-sanitize the non-emoji text. The code looks pretty okay, with no obvious problems, so it gets pushed out.
This is the sort of thing that I suspect is *all over* every semi-clever agilely-developed app, waiting to be uncovered as soon as a mischievious Austrian teenager accidentally hits the wrong key. Most applications simply don’t have enough users for these bugs to surface yet, and many will die out before they ever do, which is a blessing in itself. Sometimes the bugs are found and fixed before they explode all over Ars Technica, either by a scrutinous engineer or by an honest user or perhaps by someone looking to claim a bug bounty.
But these generally aren’t bugs that can be trivially prevented, unless the developer who’s working on improving emoji rendering for your project also happens to have enough of a security background to know that changing some safe innerHTML to the nodeValue of the safe innerHTML will suddenly create dangerous innerHTML. Or perhaps if you had a dedicated person reviewing each commit for security holes as it comes in, or at least a pre-release hook for automated fuzz testing to check for unwanted script execution, but last I checked, nobody was telling web application devs to do this.
My favorite solution is actually for everyone to just deal with being XSSed semi-frequently in the future. This means that developers should stop exposing sensitive tokens to javascript (or quickly expire tokens that are), use safe CSP directives whenever possible, and make it easy for users to review and undo actions. On the other side of the bargain, users should either start using NoScript-like browser settings to whitelist Javascript or at least blacklist known Rickroll links.