May 25, 2016
On the day that I am scheduled to see my friend Chelsea for the first time in six years, I wake up at 4:51pm to a shrieking fire alarm in my hotel room. Semi-conscious and disoriented, I leap out of bed and spin around wildly grabbing at all the things I care about – my phone and passport, the precious slip of paper that will allow me entrance to Fort Leavenworth prison, the bag of quarters that Chelsea asked me to bring – ready for an FBI raid disguised as a fire drill. Before I finish putting on shoes, the alarm stops. Slowly the wave of paranoia in my stomach grinds to a halt.
I make myself be still and breathe for a moment, reabsorbing my surroundings. I’m standing on the fourth floor of a modest hotel on the edge of Fort Leavenworth, Kansas. Outside the window looms a blue-grey sky, a vast horizon dense and textured like charcoal mixed with cream. The land is flat, green, fertile, midwestern. A hot humid river is all that separates us from Missouri. To people like Chelsea and me, who grew up in Oklahoma and Missouri before running away to sharp-edged cities by the sea, this place feels simultaneously homelike and suffocating.
As boring as Kansas is, you have to award it points for charm. Ex: a steakhouse across from the old Ft Leavenworth prison proudly proclaims itself “The Little Steak House Across from the Big House,” betraying no awareness of dark irony. The prison staff are all exceedingly polite and helpful, even when they are reprimanding me for not having a driver’s license, even when the receptionist mistakenly refers to Chelsea as “he” over a dozen times in a 5 minute phone call. “Now you go and have yourself a good day, honey,” they say in a warm-hued drawl as I navigate another step in the military bureaucracy, inching closer to actually being able to see Chelsea.
For the curious, here is approximately the process I went through to gain visitation access to the Ft Leavenworth Disciplinary Barracks:
December 2015: Chelsea adds me to her list of telephone contacts and starts the application process for my visitation, which requires evidence that we were acquainted prior to her confinement.
March/April 2016: I receive a letter notifying me that my visitation was approved but a background check is required prior to the visit. Over the course of a week or two, I called at least five different offices at Fort Leavenworth to inquire about how to do the background check before flying to Kansas. Nobody really knew, so I gave up and just booked a flight.
May 2016: After confirming via phone that I was on the Fort Leavenworth visit schedule, I fly to Kansas City. My trip companions and I check in at the Visitor Control Center to register our vehicle and get access passes to the fort. One of us is denied for having a non-US passport. The other two of us are given passes promptly and without background checks. After that, the two of us are free to drive on and off the army base.
If all goes well, I will be Chelsea’s first visitor since her sister in November.
At 6:20pm on May 24, we drive into Fort Leavenworth for the first time. I am surprised to discover that it is full of grassy fields, lush tree-lined sidewalks, and pastel suburban houses, not at all like a place where you would put a military prison. I wave at some joggers.
At 6:50pm, we finally find the United States Discipline Barracks, home of Chelsea’s prison cell. I walk inside and follow the signs to the visitation area. There are rules for visitation printed on the wall, which I’ve read a half-dozen times (no low-cut clothing, no short pants or skirts, 5 sheets of paper allowed, pencils and pens allowed, quarters and cash allowed in a transparent ziplock bag, no WiFi-enabled devices, no jackets, no cameras). The guard is friendly and makes light conversation with me, like all the Fort Leavenworth staff members I’ve interacted with so far. How bizarre to think that these friendly people, dripping with syrup-thick midwestern hospitality, are the same people keeping Chelsea forcibly isolated from the outside world for the next three decades.
I force out a weak smile, explain my visitation purpose in my a faintly-artificial Missouri accent. The guard sees me on the visit schedule but is concerned that my shirt doesn’t have sleeves. Apparently sleeveless shirts are not allowed, even though this isn’t printed anywhere in the rules. Fuck. He goes to consult another officer. I nervously fidget.
Thankfully, it is decided that I am allowed to enter (though I must wear a sleeved shirt next time). They let me through the metal detector after inspecting my 5 sheets of paper and ziplock bag containing 6 pencils, 1 pen, and $10 in quarters. I am flooded with relief, which quickly washes away into nervousness as I enter the visit room where Chelsea, my friend who I haven’t seen in six years, who I thought I would never see again after her arrest, is supposedly waiting.
She’s not there. Instead there’s just some grey tables and chairs, depressingly few of which are occupied by inmates and their sad-looking visitors.
And then the door opens and she walks in.
We run towards each other.
We hug, and my eyes fill with tears.
When something that you’ve convinced yourself will never happen is finally happening, there’s a moment when your brain starts to panic and desperately record every detail, fearing that this is all an illusion that will soon dissolve without a trace. So I looked at her as if I would never see her again, my heart sinking with the realization that there will probably never exist a photo of Chelsea Manning, age 28, for the world to see. It made me sad, because she looks nothing like any of the photos of her on the Internet. She looked like a hero, brighter and stronger than in all my memories, radiant with a light that makes no sense.
She was wearing a brown prison uniform that was too big for her small frame and smiling ear-to-ear. Her hair was neatly combed in a short pixieish cut, no longer than the 2-inch maximum allowed by the prison. Despite everything, she looked even younger than I remembered, with glowing skin and large blue eyes framed by elegant cheekbones. We beamingly smiled at each other for several seconds, suspended in disbelief and joy.
“So do you wanna sit down?” I say. We find a table, and smile some more, and then I ask if she wants anything from the vending machines. “Sure, I’ll get something I’m not usually able to get,” she says, picking a Mountain Dew. I pay for it using 6 quarters from my ziplock bag. I also try to buy her some sour cream-flavored chips, but the snacks machine is broken, which makes me unusually angry. I make a mental reminder to ask the prison staff to fix it.
We sit back down and talk for most of two hours without pausing. We talk about life in prison, where she spends 40 hours a week working in a wood shop and somehow finds time to take college correspondence courses, read journals, write a column for The Guardian, and work with lawyers on her appeal. We talk about her growing interest in post-quantum cryptography and the collection of books building up in her cell. We talk about the last time we met and what our mutual friends are up to nowadays. We talk about our complex relationships with family. We talk about my shoes (which she likes a lot) and the kind of music that she used to DJ. We talk about where she would live if she weren’t in prison. We talk about how she find motivation to keep going every day, even though some days her life feels unfair and hopeless. Many times, I am speechlessly awed by her curiosity and perseverance in the face of extremely messed-up, depressing circumstances.
I bring up her recent appeal to reduce her sentence from 35 years to 10 years, and she seems worried that it didn’t receive enough coverage in the press. She hopes that the world hasn’t forgotten about her.
I’m not sure what to say. Like others, I feel guilty for not doing more to raise public awareness for her case. Maybe if I’d spoken up more about how her sentence was grossly unjust, or written about the importance of her trial as a precedent for all whistleblowers, she’d be in a better place now. Instead all I could do was sit and chat with her, drinking soda in a sterile grey room while someone’s toddler screamed and cried at the table next to us.
Before I realize it, it’s 9:25pm and the guard is yelling at us that our time is up. Chelsea, a self-identified extrovert, seems sad that I’m leaving, even though I’ll be back in 22 hours for my second and last day of visitation. We say our goodbyes and hug each other, holding the embrace longer this time.
Back outside, I stand and watch the inmates’ families pile into their cars and drive home. Some of them live near the prison so they can visit their imprisoned loved one every day. I think about how strange it is that Chelsea is a hero to thousands if not millions of people, but there is nobody who does this for her. If she’s lucky, she’ll receive one more visit from a friend this year.
I don’t want us to forget her at least.
Update (5/26/16): Obligatory reminder that you can support Chelsea by donating to her defense fund, writing her a letter (she reads every single one she receives), and following her accounts on Twitter and Medium. In addition, this page has a nice toolkit for organizers to support her cause.
Update (6/02/16): Part 2 of this story is up for those who want to keep reading.
May 4, 2016
i turn 25 in an hour. this seems strange and unbelievable. surely 25 years of existence is enough to become acquainted with the monotonicity of time. but instead the seconds pass and disbelief stares back, unmoving.
a quarter-century is a long time. with sadness, i realize how much of it i have forgotten already.
imagine that we could live forever. would we still talk about wasting time if time were an unlimited resource? would we still apologize for being late?
it seems that we should panic less about wasting time as our lifespan grows. paradoxically, every moment in time is unique and unrepeating, so we should be losing our shit over each precious second that passes.
i used to imagine the movement of time as like a river, flowing by with the blended grace and strength of water and gravity. now it feels like a tired jogger limping by on a rhythmless gait, wrecked with joint pain and gasping for air. most steps are slogged with exhaustion, but every once in a while a wave of endorphins crashes in and makes the world spin with brightness.
how unfortunate it is to be alive during the brief window of history when computers are getting faster just as your body is getting slower. i hope i’m lucky enough to become more of a computer soon.
Dec 17, 2015
Dear Chelsea,
You probably don’t remember me, but we met in September 2009. This was before everyone knew your name and before many people knew mine.
I was at home, helping my friend cut her hair. Out of the corner of my eye, I saw you walk into the living room. You were taking photos of our mural-covered walls, seemingly happy to be in such a bizarre and interesting house of MIT students. Someone introduced you to me.
That evening, or perhaps the evening after, I learned that you were a soldier training for Iraq. You wanted to leave the military someday and get a degree in Computer Science. You weren’t much older than me, but you sounded more anxious and weary than anyone I’d ever met before. We chatted for a while, and then I had to go finish my homework.
You left Boston soon after that, and you friended me on Facebook. I accepted your friend request, and that was the last time we interacted with each other.
When you were arrested in 2010, I was proud of what you’d done and angry at what happened to you after (I still am, every day). At the same time, the media started suspecting (baselessly) that friends of mine had assisted you in whistleblowing. For the first time in my life, I felt like I might be under more surveillance than the average 18 year-old.
It was then that I realized that although I hadn’t done anything wrong, I had reason to be distrustful of the government that I lived under. I had nothing to hide, but nonetheless I was now part of a community under suspicion of a serious crime.
I started learning about security and privacy. Soon after, I installed PGP and started using it. Years later, I still think of you every time I help others encrypt their communications.
So thanks for teaching me how to be paranoid. Thanks for showing me why everyone should care about surveillance, even if they aren’t a whistleblower. Meeting you was an accident that could have happened to anyone. I’m glad it happened to me.
Happy 28th Birthday.
-Yan
[PS for readers: You can help support Chelsea by donating to her legal defense team. Info here.]
Oct 27, 2015
Every so often, I get sick of basically everything. Walls become suffocating, routine is insufferable, and the city I live in wraps itself against the sky like a cage. So inevitably I duck away and find something to chase (warm faces, the light in autumn, half-formed schemes, etc.), run until I’m dizzy and lost and can’t remember whose couch I’m waking up on or why I crashed there. Weeks later, the sky bruises into swollen dusk, some familiar voice yells for me to come home so I run back into my bed once again, wondering if home is this place more than it is the feeling of staring at an unfamiliar timetable and noticing your heartbeat quicken.
This kinda happened last month so I took a 4 week leave (2 paid, 2 unpaid) from my job to read books, work on open source projects, and couchsurf the East Coast. I spent a lot of rainy days curled up on a friend’s bed in Somerville, MA poking at my laptop, idle afternoons hiding in a corner of the MIT library poking at my laptop, and long electric evenings walking around New York City looking for a place to sit and poke at my laptop. A lot of laptop-poking happened while on “vacation” because I had promised some people that I would give two talks in October, one at SecretCon and one at ToorCon.
Predictably, I put off the ToorCon talk until 2 weeks ago. Also predictably, I started panicking and not sleeping anymore because I said I would show people a new browser fingerprinting technique which did not exist. Somehow, after a lot of head-banging-against-desk, I came up with one that sort-of worked about a week before the ToorCon and actually finished the code right before ToorCon. I named it Sniffly because it sniffs browser history, and also because I was coming down with a cold.
Here’s how Sniffly works:
- A user visits the Sniffly page.
- Their browser attempts to load images from various HSTS domains over HTTP. These domains were harvested from a scrape of HSTS domains in the Alexa Top 1M. It was really fun to write this scraper; I finally had a chance to use Python’s Twisted!
- Sniffly sets a CSP policy that restricts images to HTTP, so image sources are blocked before they are redirected to HTTPS. This is crucial, because If the browser completes a request to the HTTPS site, then it will receive the HSTS pin, and the attack will no longer work when the user visits Sniffly.
- When an image gets blocked by CSP, its
onerror handler is called. In this case, the onerror handler does some fancy tricks to semi-reliably time how long it took for the image to be redirected from HTTP to HTTPS. If this time is on the order of a millisecond, it was an HSTS redirect (no network request was made), which means the user has visited the image’s domain before. If it’s on the order of 100 milliseconds, then a network request probably occurred, meaning that the user hasn’t visited the image’s domain.
Here’s a quick demo. It only works in recent Chrome/Firefox versions when HTTPS Everywhere is disabled. The results also turn up a lot of false positives if you are running an adblocker, since ad-blocked domains are indistinguishable from HSTS-blocked domains from a timing perspective. (However, since HTTPS Everywhere domains and ad-blocked domains are mostly the same for every user, they can simply be subtracted out to get more accurate results for users who run these browser extensions.) I didn’t collect analytics on the site, but random testing with several friends showed a ~80% accuracy rate in the demo once browser extensions were accounted for.
For more info, check out the source code, ToorCon slides (pdf), and talk recording. Someone submitted the demo to Hacker News and, to my horror, it was the #1 link for 6+ hours yesterday (!). I feel bewildered that this kind of attention is being granted (again) to random side projects that I do alone in my spare time, but I guess I should take whatever validation I can get right now. It would be sweet if people looked at my work and paid me to hack on interesting stuff for the public so i never had to work a real job again. Maybe someday it’ll happen; until then I’ll prolly hold down a day job and take more fake vacations.
Update: As of March 2016, Sniffly (CVE-2016-1617) has been fixed in the major browsers. Thank you Uncle Google for the bug bounty $$.
Oct 26, 2015
you know things are getting better when you walk away from the hotel where you just gave two presentations wearing your best pretense of holding-it-togetherness while inside you felt shakey, hungover, and insane. remember how long you stood there, smiling and rationing weak handshakes while pretending you believed that you had a future? promise yourself you’re never doing that again. you walk away from the volatile company of people who made you feel shitty about yourself without trying to and into the car of someone who looks like they could be your new friend. you drive down the street and pack your bags, take off your stupid clothes and pull on a grey tshirt. now you’re driving down Highway 5 towards LA, the hills are honey-colored, the mountains crashing into sunset sky with symphonic grace, your insecurities start to crack like chipped gold paint. you pick at your wrecked fingernails and start to feel like you might have the vaguest idea of what to do with yourself tomorrow morning. then your new friend turns on the stereo and says, “do you want to hear a song i wrote? it’s about how my mom was a cunt.” you say, sure.
Aug 24, 2015
In addition to unforgettable life experiences and personal growth, one thing I got out of DEF CON 23 was a copy of POC||GTFO 0x08 from Travis Goodspeed. The coolest article I’ve read so far in it is “Deniable Backdoors Using Compiler Bugs,” in which the authors abused a pre-existing bug in CLANG to create a backdoored version of sudo that allowed any user to gain root access. This is very sneaky, because nobody could prove that their patch to sudo was a backdoor by examining the source code; instead, the privilege escalation backdoor is inserted at compile-time by certain (buggy) versions of CLANG.
That got me thinking about whether you could use the same backdoor technique on javascript. JS runs pretty much everywhere these days (browsers, servers, arduinos and robots, maybe even cars someday) but it’s an interpreted language, not compiled. However, it’s quite common to minify and optimize JS to reduce file size and improve performance. Perhaps that gives us enough room to insert a backdoor by abusing a JS minifier.
Part I: Finding a good minifier bug
Question: Do popular JS minifiers really have bugs that could lead to security problems?
Answer: After about 10 minutes of searching, I found one in UglifyJS, a popular minifier used by jQuery to build a script that runs on something like 70% of the top websites on the Internet. The bug itself, fixed in the 2.4.24 release, is straightforward but not totally obvious, so let’s walk through it.
UglifyJS does a bunch of things to try to reduce file size. One of the compression flags that is on-by-default will compress expressions such as:
!a && !b && !c && !d
That expression is 20 characters. Luckily, if we apply De Morgan’s Law, we can rewrite it as:
!(a || b || c || d)
which is only 19 characters. Sweet! Except that De Morgan’s Law doesn’t necessarily work if any of the subexpressions has a non-Boolean return value. For instance,
!false && 1
will return the number 1. On the other hand,
!(false || !1)
simply returns true.
So if we can trick the minifier into erroneously applying De Morgan’s law, we can make the program behave differently before and after minification! Turns out it’s not too hard to trick UglifyJS 2.4.23 into doing this, since it will always use the rewritten expression if it is shorter than the original. (UglifyJS 2.4.24 patches this by making sure that subexpressions are boolean before attempting to rewrite.)
Part II: Building a backdoor in some hypothetical auth code
Cool, we’ve found the minifier bug of our dreams. Now let’s try to abuse it!
Let’s say that you are working for some company, and you want to deliberately create vulnerabilities in their Node.js website. You are tasked with writing some server-side javascript that validates whether user auth tokens are expired. First you make sure that the Node package uses uglify-js@2.4.23, which has the bug that we care about.
Next you write the token validation function, inserting a bunch of plausible-looking config and user validation checks to force the minifier to compress the long (not-)boolean expression:
function isTokenValid(user) {
var timeLeft =
!!config && // config object exists
!!user.token && // user object has a token
!user.token.invalidated && // token is not explicitly invalidated
!config.uninitialized && // config is initialized
!config.ignoreTimestamps && // don't ignore timestamps
getTimeLeft(user.token.expiry); // > 0 if expiration is in the future
// The token must not be expired
return timeLeft > 0;
}
function getTimeLeft(expiry) {
return expiry - getSystemTime();
}
Running uglifyjs -c on the snippet above produces the following:
function isTokenValid(user){var timeLeft=!(!config||!user.token||user.token.invalidated||config.uninitialized||config.ignoreTimestamps||!getTimeLeft(user.token.expiry));return timeLeft>0}function getTimeLeft(expiry){return expiry-getSystemTime()}
In the original form, if the config and user checks pass, timeLeft is a negative integer if the token is expired. In the minified form, timeLeft must be a boolean (since “!” in JS does type-coercion to booleans). In fact, if the config and user checks pass, the value of timeLeft is always true unless getTimeLeft coincidentally happens to be 0.
Voila! Since true > 0 in javascript (yay for type coercion!), auth tokens that are past their expiration time will still be valid forever.
Part III: Backdooring jQuery
Next let’s abuse our favorite minifier bug to write some patches to jQuery itself that could lead to backdoors. We’ll work with jQuery 1.11.3, which is the current jQuery 1 stable release as of this writing.
jQuery 1.11.3 uses grunt-contrib-uglify 0.3.2 for minification, which in turn depends on uglify-js ~2.4.0. So uglify-js@2.4.23 satisfies the dependency, and we can manually edit package.json in grunt-contrib-uglify to force it to use this version.
There are only a handful of places in jQuery where the DeMorgan’s Law rewrite optimization is triggered. None of these cause bugs, so we’ll have to add some ourselves.
Backdoor Patch #1:
First let’s add a potential backdoor in jQuery’s .html() method. The patch looks weird and superfluous, but we can convince anyone that it shouldn’t actually change what the method does. Indeed, pre-minification, the unit tests pass.
After minification with uglify-js@2.4.23, jQuery’s .html() method will set the inner HTML to “true” instead of the provided value, so a bunch of tests fail.
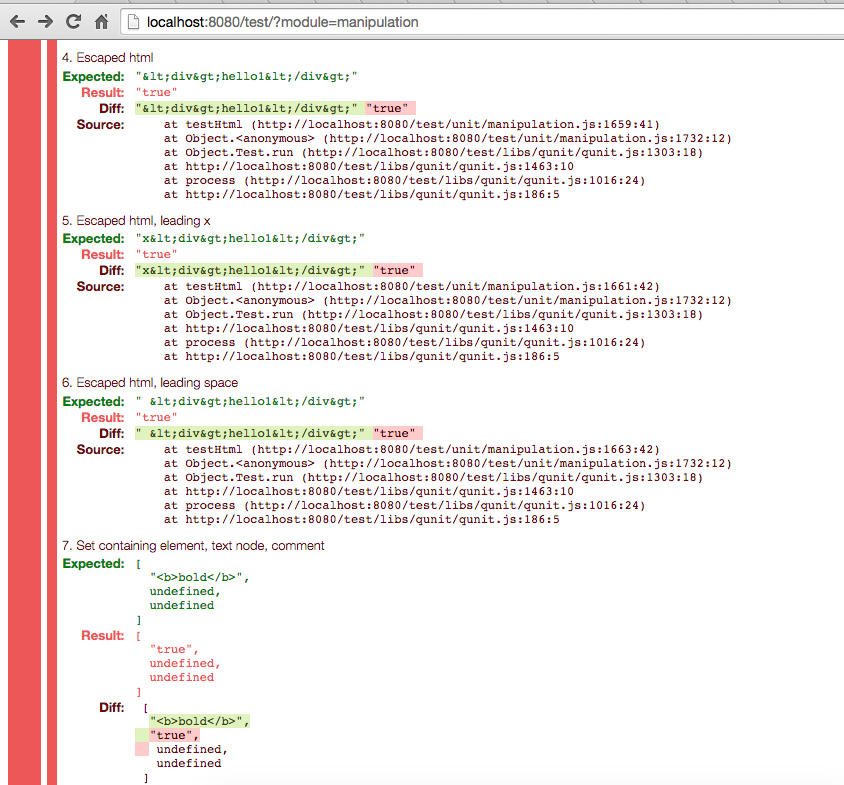
However, the jQuery maintainers are probably using the patched version of uglifyjs. Indeed, tests pass with uglify-js@2.4.24, so this patch might not seem too suspicious.
Cool. Now let’s run grunt to build jQuery with this patch and write some silly code that triggers the backdoor:
<html>
<script src="../dist/jquery.min.js"></script>
<button>click me to see if this site is safe</button>
<script>
$('button').click(function(e) {
$('#result').html('<b>false!!</b>');
});
</script>
<div id='result'></div>
</html>
Here’s the result of clicking that button when we run the pre-minified jQuery build:
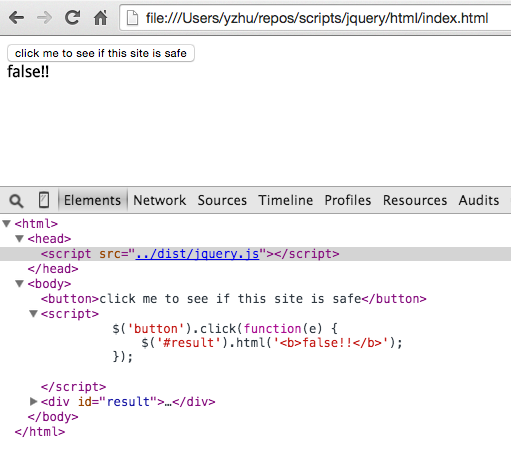
As expected, the user is warned that the site is not safe. Which is ironic, because it doesn’t use our minifier-triggered backdoor.
Here’s what happens when we instead use the minified jQuery build:
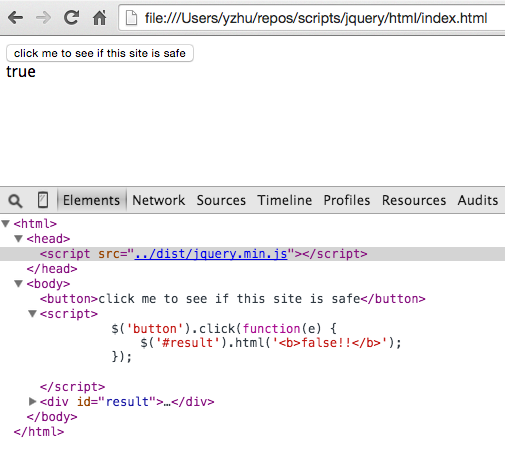
Now users will totally think that this site is safe even when the site authors are trying to warn them otherwise.
Backdoor Patch #2:
The first backdoor might be too easy to detect, since anyone using it will probably notice that a bunch of HTML is being set to the string “true” instead of the HTML that they want to set. So our second backdoor patch is one that only gets triggered in unusual cases.
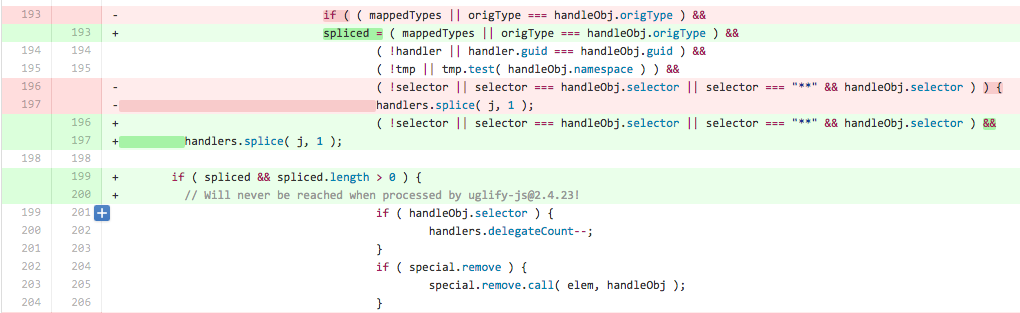
Basically, we’ve modified jQuery.event.remove (used in the .off() method) so that the code path that calls special event removal hooks never gets reached after minification. (Since spliced is always boolean, its length is always undefined, which is not > 0.) This doesn’t necessarily change the behavior of a site unless the developer has defined such a hook.
Say that the site we want to backdoor has the following HTML:
<html>
<script src="../dist/jquery.min.js"></script>
<button>click me to see if special event handlers are called!</button>
<div>FAIL</div>
<script>
// Add a special event hook for onclick removal
jQuery.event.special.click.remove = function(handleObj) {
$('div').text('SUCCESS');
};
$('button').click(function myHandler(e) {
// Trigger the special event hook
$('button').off('click');
});
</script>
</html>
If we run it with unminified jQuery, the removal hook gets called as expected:
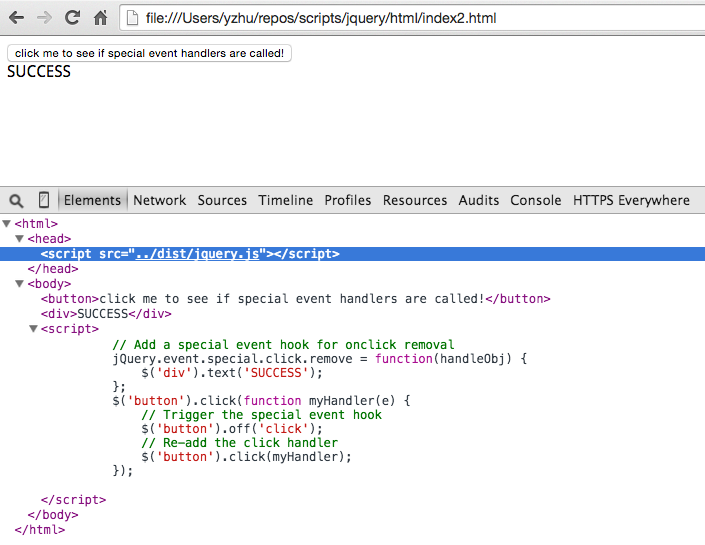
But the removal hook never gets called if we use the minified build:
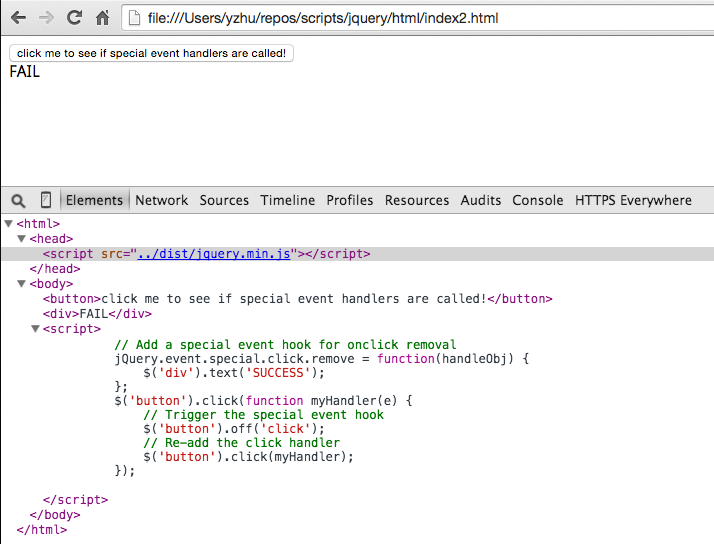
Obviously this is bad news if the event removal hook does some security-critical function, like checking if an origin is whitelisted before passing a user’s auth token to it.
Conclusion
The backdoor examples that I’ve illustrated are pretty contrived, but the fact that they can exist at all should probably worry JS developers. Although JS minifiers are not nearly as complex or important as C++ compilers, they have power over a lot of the code that ends up running on the web.
It’s good that UglifyJS has added test cases for known bugs, but I would still advise anyone who uses a non-formally verified minifier to be wary. Don’t minify/compress server-side code unless you have to, and make sure you run browser tests/scans against code post-minification. [Addendum: Don’t forget that even if you aren’t using a minifier, your CDN might minify files in production for you. For instance, Cloudflare’s collapsify uses uglifyjs.]
Now, back to reading the rest of POC||GTFO.
PS: If you have thoughts or ideas for future PoC, please leave a comment or find me on Twitter (@bcrypt). The code from this blog post is up on github.
[Update 1: Thanks @joshssharp for posting this to Hacker News. I’m flattered to have been on the front page allllll night long (cue 70’s soul music). Bonus points – the thread taught me something surprising about why it would make sense to minify server-side.]
[Update 2: There is now a long thread about minifiers on debian-devel which spawned this wiki page and another HN thread. It’s cool that JS developers are paying attention to this class of potential security vulnerabilities, but I hope that people complaining about minification also consider transpilers and other JS pseudo-compilers. I’ll talk more about that in a future blog post.]
Jul 26, 2015
FYI: this post is an artifact of the Dark Ages when my blog was self-hosted WordPress. Let us not speak of that time.
Having recently given some talks about Content Security Policy (CSP), I decided just now to enable it on my own blog to prevent cross-site scripting.
This lil’ blog is hosted by the MIT Student Information Processing Board and runs on a fairly-uncustomized WordPress 4.x installation. Although I could have enabled CSP by modifying my .htaccess file, I chose to use HTML tags instead so that these instructions would work for people who don’t have shell access to their WordPress host. Unfortunately, CSP using hasn’t landed in Firefox yet (tracking bug) so I should probably do the .htaccess thing anyway.
It’s pretty easy to turn on CSP in WordPress from the dashboard:
- Go to <your_blog_path>/wp-admin/theme-editor.php. Note that this isn’t available for WordPress-hosted blogs (*.wordpress.com).
- Click on Header (header.php) in the sidebar to edit the header HTML.
- At the start of the HTML
<head> element, add a CSP meta tag with your CSP policy. This blog uses <meta http-equiv="Content-Security-Policy" content="script-src 'self'"> which disallows all scripts except from its own origin (including inline scripts). As far as I can tell, this blocks a few inline scripts but doesn’t impede any functionality on a vanilla WordPress instance. You might want a more permissive policy if you use fancy widgets and plugins.
- [Bonus points] You can also show a friendly message to users who disable javascript by adding a
<noscript> element to your header.
A fun fact I discovered during this process is that embedding a SoundCloud iframe will include tracking scripts from Google Analytics and scorecardresearch.com. Unfortunately CSP on the embedding page (my blog) doesn’t extend to embedded contexts (soundcloud.com iframe), so those scripts will still run unless you’ve disabled JS.
That’s all. I might do more posts on WordPress hardening later or even write a WP plugin (*shudders at the thought of writing PHP*). More tips are welcome too.
UPDATE (8/24/15): CSP is temporarily disabled on this blog because Google Analytics uses an inline script. I’ll nonce-whitelist it later and turn CSP back on.
Jul 17, 2015
Greetings from the beautiful museum district of Berlin, where I’ve been trapped in a small conference room all week for the quarterly meeting of the W3C Technical Architecture group. So far we’ve produced two documents this week that I think are pretty good:
I just realized I have a few more things to say about the latter, based on my experience building and maintaining a semi-popular ad blocker (Privacy Badger Firefox).
- Beware of ad blockers that don’t actually block requests to tracking domains. For instance, an ad blocker that simply hides ads using CSS rules is not really useful for preventing tracking. Many users can’t tell the difference.
- Third-party cookies are not the only way to track users anymore, which means that browser features and extensions that only block/delete third-party cookies are not as useful as they once were. This 2012 survey paper [PDF] by Jonathan Mayer et. al. has a table of non-cookie browser tracking methods, which is probably out of date by now:

- Detecting whether a domain is performing third-party tracking is not straightforward. Naively, you could do this by counting the number of first-party domains that a domain reads high-entropy cookies from in a third-party context. However, this doesn’t encompass reading non-cookie browser state that could be used to uniquely identify users in aggregate (see table above). A more general but probably impractical approach is to try to tag every piece of site-readable browser state with an entropy estimate so that you can score sites by the total entropy that is readable by them in a third-party context. (We assume that while a site is being accessed as a first-party, the user implicitly consents to letting it read information about them. This is a gross simplification, since first parties can read lots of information that users don’t consent to by invisible fingerprinting. Also, I am recklessly using the term “entropy” here in a way that would probably cause undergrad thermodynamics professors to have aneurysms.)
- The browser definition of “third-party” only roughly approximates the real-life definition. For instance, dropbox.com and dropboxusercontent.com are the same party from a business and privacy perspective but not from the cookie-scoping or DNS or same-origin-policy perspective.
- The hardest-to-block tracking domains are the ones who cause collateral damage when blocked. A good example of this is Disqus, commonly embedded as a third-party widget on blogs and forums; if we block requests to Disqus (which include cookies for logged-in users), we severely impede the functionality of many websites. So Disqus is too usability-expensive to block, even though they can track your behavior from site to site.
- The hardest-to-block tracking methods are the ones that cause collateral damage when disabled. For instance, HSTS and HPKP both store user-specific persistent data that can be abused to probe users’ browsing histories and/or mark users so that you can re-identify them after the first time they visit your site. However, clearing HSTS/HPKP state between browser sessions dilutes their security value, so browsers/extensions are reluctant to do so.
- Specifiers and implementers sometimes argue that Feature X, which adds some fingerprinting/tracking surface, is okay because it’s no worse than cookies. I am skeptical of this argument for the following reasons:
a. Unless explicitly required, there is no guarantee that browsers will treat Feature X the same as cookies in privacy-paranoid edge cases. For instance, if Safari blocks 3rd party cookies by default, will it block 3rd party media stream captures (which will store a unique deviceid) by default too?
b. Ad blockers and anti-tracking tools like Disconnect, Privacy Badger, and Torbutton were mostly written to block and detect tracking on the basis of cookies, not arbitrary persistent data. It’s arguable that they should be blocking these other things as soon as they are shipped in browsers, but that requires developer time.
That’s all. And here’s some photos I took while walking around Berlin in a jetlagged haze for hours last night:


Update (7/18/15): Artur Janc of Google pointed out this document by folks at Chromium analyzing various client identification methods, including several I hadn’t thought about.
Jun 7, 2015
The combination of my roommate starting a Rust podcast and a long, animated conversation with a (drunk) storyteller last night caused me to become suddenly enamored with the idea of starting my own lil’ podcast. Lately I keep thinking about how many spontaneous, insightful conversations are never remembered, much less entombed in a publicly-accessible server for posterity. So a podcast seemed like an excellent way to share these moments without spending a lot of time writing (I’m a regrettably slow writer). I’d simply bring folks into my warehouse living room, give them a beverage of their choice, and spend a leisurely hour chatting about whatever miscellaneous topics came to mind.
And so, wasting no time, today I asked my ex-ex-colleague Peter Eckersley if he would like to be my first podcast guest. Peter runs the technology projects team at the Electronic Frontier Foundation and, more importantly, lives 3 blocks away from me. Fortuitously, Peter agreed to have me over for a chat later this afternoon.
When I arrived, it turned out that one of Peter’s housemates was having friends over for dinner, so finding a quiet spot became a challenge. We ended up in a tiny room at the back of his house where every flat surface was covered in sewing equipment and sundry household items. As Peter grabbed a hammer to reconstruct the only available chair in the room, I set up my laptop and fancy (borrowed) podcast microphone. We gathered around as close as we could and hit the record button.
Except for one hiccup where Audacity decided to stop recording abruptly, the interview went smoothly and didn’t need much editing. Next time I’ll plan to put myself closer to the mic, do a longer intro, and maybe cut the length down to 15 minutes.
Here is the result.
Overall, I had a fun time recording this podcast and am unduly excited about future episodes. Turns out a podcast takes ~10% of the time to write a blog post with the same content. 🙂
For this and future episodes in the Pseudorandom Podcast Series, here’s an RSS feed. I’m going to reach SoundCloud’s limit of 180 minutes real quick at this rate, so I will probably host these somewhere else in the future or start a microfunding campaign to pay $15/month.
Apr 27, 2015
i’ve finally recovered enough from a multi-week bout of sickness to say some things and put up some photos. lately i’ve felt exhausted and lethargic and unproductive to be honest. being sick probably had something to do with it; i sure hope next week gets better.
yesterday, someone told me they had a theory that everyone who sleeps at night (with rare exceptions) can only manage ~3 significant life events at a time. that sounds about right, but it feels like a lot has been going on. a partial, unordered list:
- talked yesterday at the Yahoo Trust Unconference about the future of email security

photo credit Bill Childers
-
working on graceful degradation of hopes and feelings
-
writing software for Let’s Encrypt as an EFF Technology fellow
-
trying to make sane w3c standards with these fine folks from the W3C Technical Architecture group

photo credit Tantek Celik
-
packing bag(s) and moving to a new neighborhood (twice)
-
finding balance on a skateboard and otherwise
“I think emotional and crypto intelligence are severely underrated” – spectator at the Yahoo Trust Unconference.






