Nov 28, 2013
One year ago, I started writing again out of panic. Humans are very adept at forgetting the feeling of panic, so the act of crystallizing it in sentences can be cathartic if you write slowly enough.
Last November was a weird and difficult time for me. I remember spending the night of the twenty-third in a friend’s childhood bedroom overlooking the idyllic frost-laced meadows of suburban Pennsylvania, wrapped in the mansion of an unfamiliar family that had adopted me for Thanksgiving. It was cold and late and Thanksgiving-y, in a way that amplifies certain negative thoughts about the hollowness of growing up and becoming something. I think I was at a point where those kinds of thoughts made me feel like I had swallowed one or two hummingbirds stuffed with bees stuffed with amphetamine. It was a little uncomfortable, so I stayed up all night and wrote about it.
That was the night I decided that I would take a leave of absence from grad school at Stanford and spend a year doing as many different jobs as I could 1. If I couldn’t find a job that I was genuinely excited about by 11/23/2013, I would go back to getting a PhD in Physics.
1 For the record, I held a total of 4 paid jobs and 1.5 unpaid ones during that time.
=====
To be honest, it kind of sucked at first. I did an apt job of writing about it back in January.
The last month or so has been full of stress, disappointment, and self-doubt, the pains of a transition to life without externally-imposed structure.
Life without structure in the form of school or employment was terrifying at first. I found it difficult to concentrate on reading. Most days I felt like I was losing in some form or another. My patterns of learning were slow and frustrating, and I started to doubt whether I was capable of accomplishing anything on my own. That’s a really horrifying doubt to have about yourself, and I interpreted it as a sign to go rearrange some psychological furniture (not literal furniture, but only because I was couchsurfing at the time and had none).
A couple days after that frankly-depressing blog post, I moved into my first San Francisco apartment and got my first post-graduation job: an internship that had some good moments (getting the company’s IP blocked from Google a couple times) but mostly involved me feeling less like a human and more like a training set for advanced machine learning algorithms with each passing day.
My second job was better. I got to write software.
=====
Winter passed into spring. I was getting close to 22. Sometimes I would run down Folsom St. all the way to the ocean, amazed that there was still light out at 7 pm. San Francisco in the dimming sunset is full of rushing cars, discarded coffee cups, and people eating salads. My bike was falling apart.
Ever since quitting grad school, I’d been getting good at leaving things behind: jobs, roommates, feelings of attachment to any particular time or place. Part of it was just that I had high standards for who I wanted to become.
San Francisco didn’t quite fit anymore, so I packed a backpack and got on a one-way flight to Boston.
=====
Once I started travelling, it was hard to stop. The crinkled packaging of snack food at a gas station convenience store is basically equivalent to the wrapping that airlines put around cheap disposable pillows. Both are addictive because they remind you of the miles you have to go.
I did this: Boston -> Delaware -> Pittsburg -> Boston -> Austin -> Marfa, TX -> El Paso -> Joshua Tree -> LA -> Big Sur -> SF -> Seattle -> SF -> a tiny village in France -> Amsterdam -> SF
=====
Things got better once I returned to SF. I was interning for EFF over the summer and loved the atmosphere and the people there enough to stay put. I didn’t have a place to live anymore in SF, so I didn’t sleep in the same place two nights in a row for over a month.
=====
Computer security and encryption became intensely fascinating. I didn’t know much to start with, so I read aggressively on subways. My interest probably came partially from my hatred of power imbalances, especially invisible ones. A lot of power belongs to those who made security decisions about software, and those decisions are hardly transparent in most cases.
This seems wrong to me.
Side note: Designing an account management system for a website teaches you that code is supplanting many of the historical functions of legal frameworks. You’d think that would mean that people would write tests.
=====
I was in Berlin for the first time last week. It was drizzling near-freezing Berlin rain for eight days before a thumbprint of blue pressed through the clouds, but none of that matters when you’re jetlagged and ducking through graffiti-lined streets asking drug dealers where to get a sandwich at 3 AM.
It was in a corner of a dimly-lit Indian restaurant in Kreuzberg one night that I got an email from EFF. It said, thanks for pointing out Google’s HSTS bug. Also we’d like to offer you a job as a full-time technologist.
The next day was November twenty-third, exactly one year after I promised myself exactly one year to find a job that I was excited about.
======
I’m proud to announce that I accepted EFF’s offer today and will be starting work there as a staff technologist after Thanksgiving. It’s been a long and challenging year, but I can’t wait to see where it goes next.
Nov 22, 2013
**Disclaimer**: This post was published before I started working at EFF, hence some stylistic mistakes (calling it “the EFF” rather than just “EFF”) are excusable and left uncorrected. 🙂
Two days ago, the EFF published a report tiled, “Encrypt the Web Report: Who’s Doing What.” The report included a chart that rated several large web companies on how well they were protecting user privacy via recommended encryption practices for data in transit. The five ranking categories were basic HTTPS support for web services, encryption of data between data centers, STARTTLS for opportunistic email encryption, support for SSL with perfect forward secrecy, and support for HTTP Strict Transport Security (HSTS). It looks like this:

By most measures, this is an amazing chart: it’s easy to understand, seems technically correct, and is tailored to address the public’s concerns about what companies are doing to protect people from the NSA. On the other hand, I don’t like it much. Here’s why:
The first problem with the report is that it inadequately explains the basis for each score. For instance, what does a green check in the “HTTPS” category mean? Does it mean that the company is encrypting all web traffic, or just web traffic for logins and sensitive information? Sonic.net certainly got a green check in that category, yet you can check that going to http://sonic.net doesn’t even redirect you to HTTPS. Amazon got a red square that says “limited”, but they seem to encrypt login and payment credentials just fine.
The second problem is that the report lacks transparency on how its data was acquired. It states, “The information in this chart comes from several sources; the companies who responded to our survey questions; information we have determined by independently examining the listed websites and services and published reports.” Does that mean the EFF sent a survey to a bunch of companies that asked them to check which boxes they thought that they fulfilled? Could we at least see the survey? Also, was each claim independently verified, or did the EFF just trust the companies that responded to the survey?
I looked at the chart for a while, re-read the text a couple times, and remained unconvinced that I should go ahead and share it with all my friends. After all, there is no greater crime than encouraging ordinary people to believe whatever large companies claim about their security practices. That just leads to less autonomy for the average user and more headaches for the average security engineer. So I decided to take a look at the HSTS category to see whether I could verify the chart myself.
For those who are unfamiliar, when a website says that they support HSTS, they generally mean that they send a special “Strict-Transport Security” header with all HTTPS responses. This header tells your browser to only contact the website over HTTPS (a secure, encrypted protocol) for a certain length of time, preferably on the order of weeks or months. This is better than simply redirecting a user to HTTPS when they try to contact the site over HTTP 1, because that initial HTTP request can get intercepted by a malicious attacker. By refusing to send the HTTP request at all and only sending the HTTPS version of it, your browser protects you from someone sending you forged HTTPS data after they’ve intercepted the HTTP request.
1 HTTP traffic can be trivially read by anyone who intercepts those packets, so you should watch out for passwords, cookies, and other sensitive data sent over HTTP. I wrote a post a while back showing how easy it is to sniff HTTP traffic with your laptop.
(HSTS is a good idea, and all servers that support HTTPS should implement it.
If you decide to stop supporting HTTPS, you can just send an HSTS header with “max-age=0.”)
But HSTS still has a problem, which is that the first time a user ever contacts a website, they’ll most likely do it over HTTP since they haven’t received the HSTS header from the site yet! The Chromium browser tried to solve this problem by coming with an HSTS Preload List, which is an ever-growing preloaded list of sites that want users to contact them over HTTPS the first time. Firefox, Chrome, and Chromium all come shipped with this list. (Fun note: HTTPS Everywhere, the browser extension by the EFF that I worked on, is basically a gigantic HSTS preload list of 7000+ domains. The difference is that the HTTPS Everywhere list doesn’t come with every browser, since it’s much less stable, so you have to install it as an extension.)
Anyway, let’s see if Google’s main search supports HSTS. To check, open up a browser and type in “http://google.com.” If it supports HSTS, the HTTP request never returns a status code. If it doesn’t support HSTS, the HTTP request returns a 302-redirect to HTTPS.
Results, examined in Firefox 25 with Firebug:
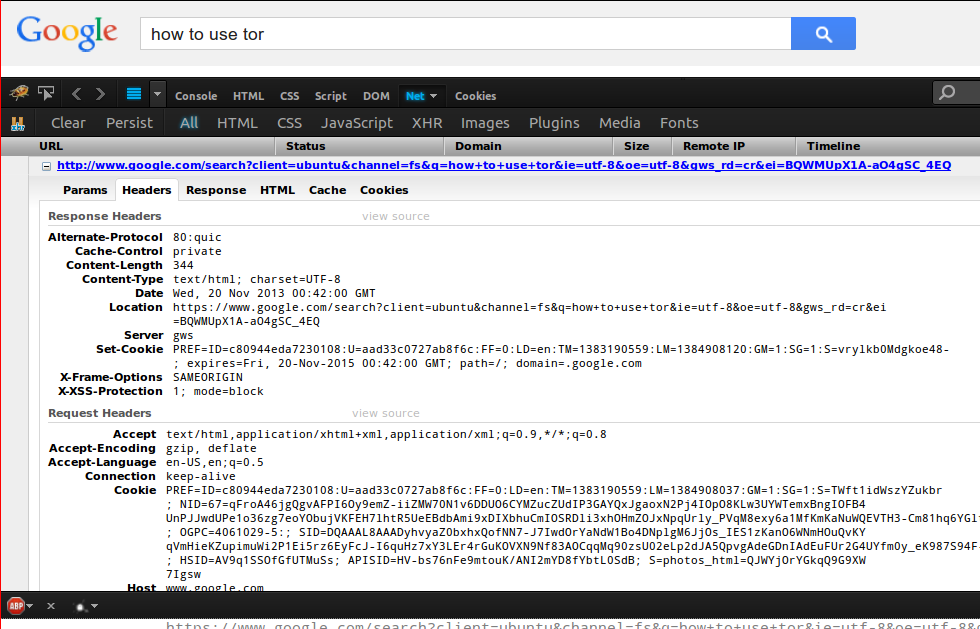
Nope! As you can see, the HTTP request completes. As it does that, it leaks our search query (“how to use tor”) and some of our preference cookies to the world.
The request then 302-redirects to HTTPS, as expected, but that HTTPS request doesn’t contain an HSTS header at all. So there’s no way that Google main search supports HSTS, at least in Firefox.
I was puzzled. Why would Google refuse to send the HSTS header, even though they support HTTPS pretty much everywhere, definitely on their main site? I did a bit more searching and concluded that it was because they deliberately send ad clicks over plain HTTP.
To prove this to yourself, do a Google search that returns some ads: for instance, “where to buy ukuleles.” If you open up Firebug’s page inspector and look at the link for the ad, which supposedly goes to a ukulele retail site, you’ll see a secret hidden link that you hit when you click on the ad! That link goes to “http://google.com/aclk?some_parameters=etc,” and you can conclude that Google wants you to click on that HTTP link because they put it in the DOM exactly where you’d want to click on it anyway.
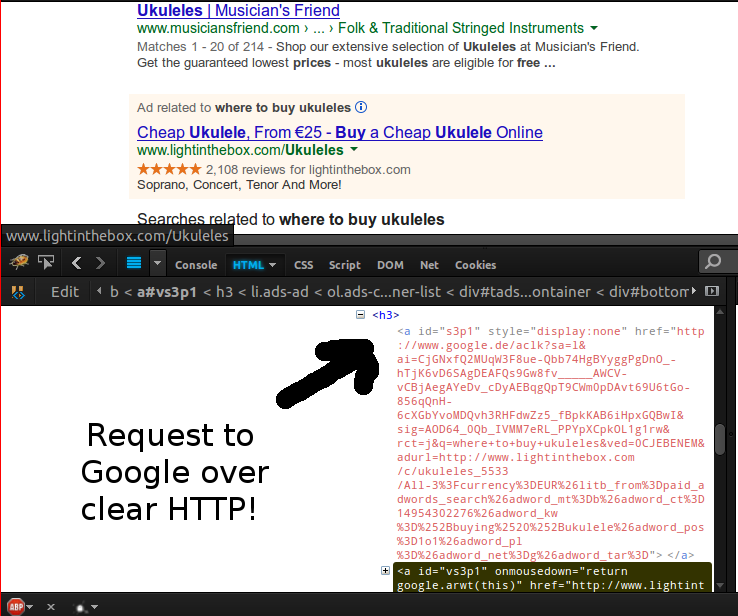
Let’s click on that ukulele link. Yep, we end up redirected to http://googleadservices.com (plain HTTP again), which leaks our referer. That means the site that posted the ad as well as the NSA and anyone sniffing traffic at your local coffeeshop can see what ads you’re looking at and what you were searching for when you clicked on them.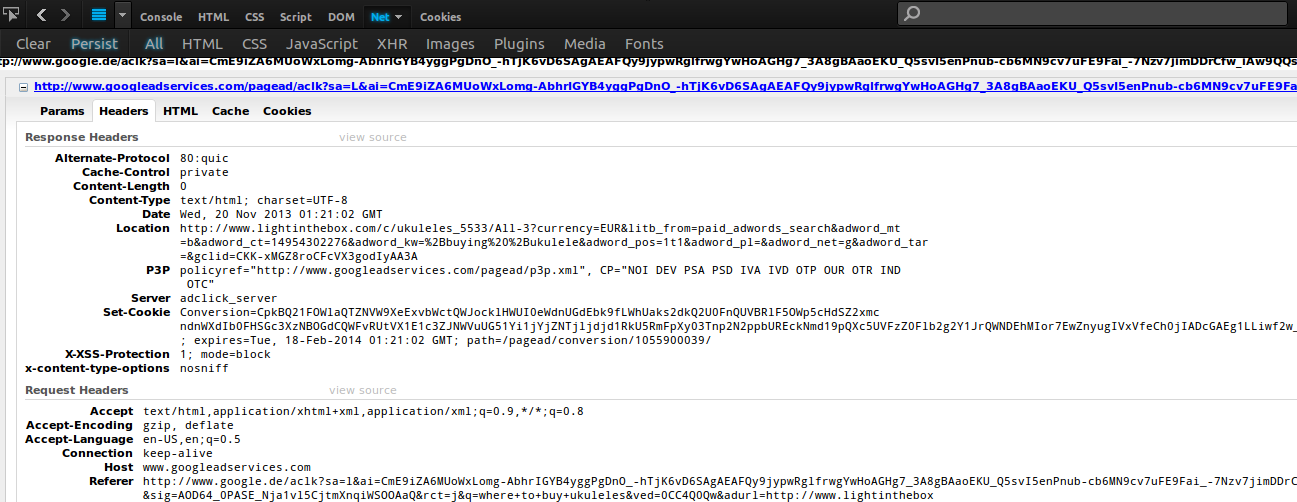
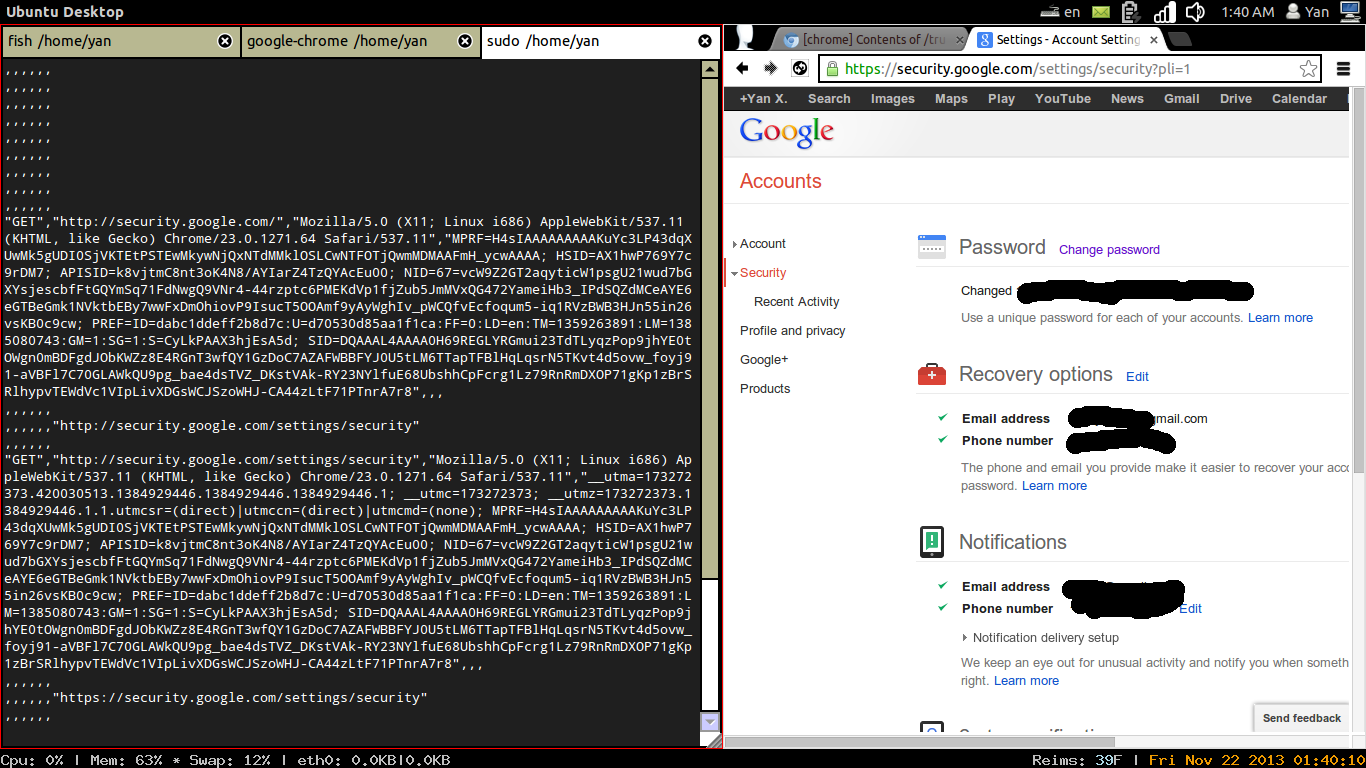
This is presumably the reason that Google.com doesn’t send the HSTS header and isn’t on the HSTS preload list. But wait, there’s plenty of Google domains that are in fact on the preload list, like mail.google.com, encrypted.google.com, accounts.google.com, security.google.com, and wallet.google.com. Don’t they send the HSTS header?
I checked in Firefox, and none of them did except for accounts.google.com. The rest all 302-redirect to HTTPS, just like any HTTPS site that doesn’t support HSTS.
Then I did a bit more reading and found out that HSTS preloads were implemented such that Firefox ignored any site on the preload list that didn’t send a valid HSTS header with an expiration time greater than 18 weeks. This seems like a valid design choice. Why would a site want to be on the preload list but not support HSTS at all for people with non-Firefox/Chrome/Chromium browsers? And if they don’t send the header in the first place, how do we know when the site stops supporting HSTS?
Given that Google doesn’t really provide the benefits of HSTS to any browsers except Chrom{e, ium}, it’s hard to argue that it deserves the green check mark in the HSTS category. The moral of the story is that the EFF is awesome, but having a healthy mistrust of what companies claim is even more awesome.
=====
[IMPORTANT EDIT (11/23/13): The following originally appeared in this post, but I’ve removed it because it turns out I was accidentally using a version of Chrome that didn’t have the HSTS preloads that I was testing for anyway. Thanks to Chris Palmer for pointing out that Chrome 23 is a year old at this point, and apologies to everyone for my error.]
Alright, so I had to also check whether Chrome respected the preload list even for sites that didn’t send the header. To be extra careful, I did this by packet-sniffing my laptop’s traffic on port 80 (HTTP) with tshark rather than examining requests with Chrome developer tools. The relevant command on a wifi network, for anyone who’s curious, is:
tshark -p port 80 -i wlan0 -T fields -e http.request.method -e http.request.full_uri -e http.user_agent -e http.cookie -e http.referer -e http.set-cookie -e http.location -E separator=, -E quote=d
Let’s try http://wallet.google.com. Yep, we leak HTTP traffic. (It then redirects to https://accounts.google.com because I haven’t logged in to Wallet yet.)
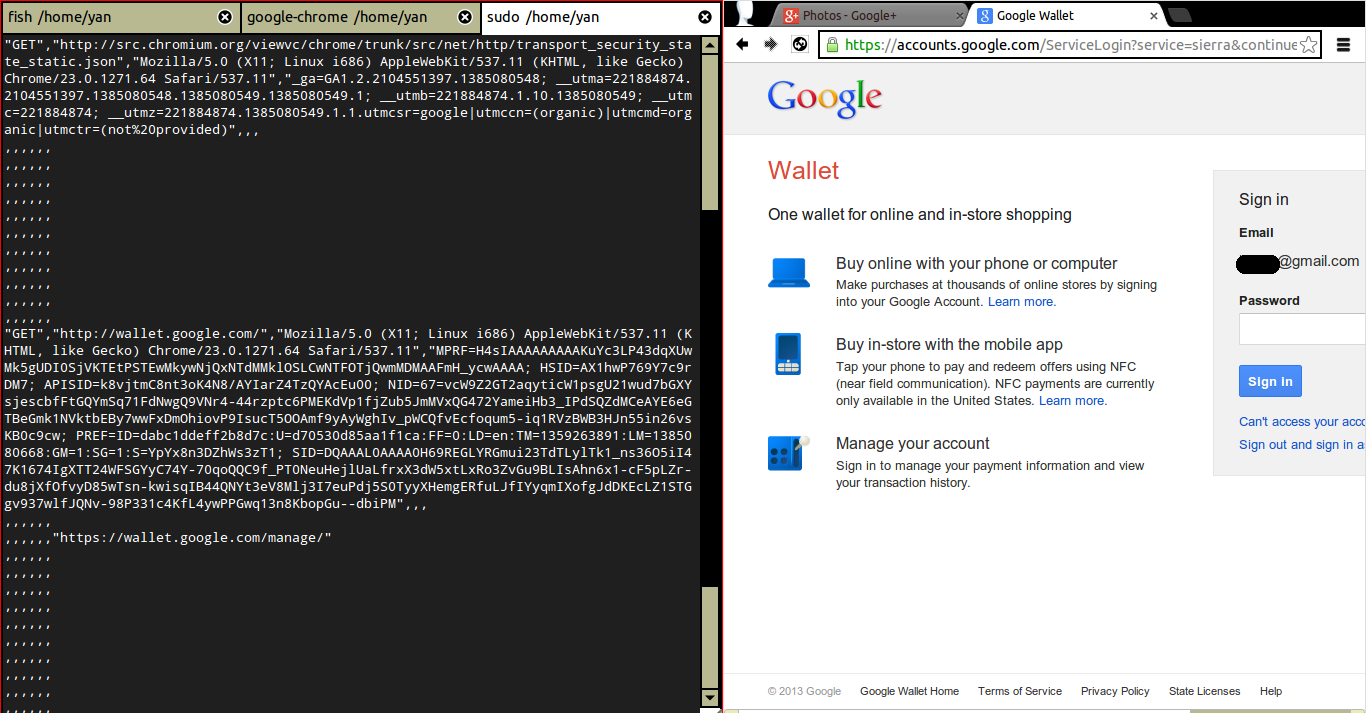
How about http://security.google.com? Yep, we leak HTTP traffic there too.
Nov 4, 2013
The following is a phenomenal story for illustrating how real-life cybersecurity disasters come from a combination of technical and social failures. In this case, both were necessary for making things as catastrophic as they were.
A couple days ago, it was announced that 130 million Adobe account credentials were compromised by a cyberattack. (If you are an Adobe customer, please make sure you’ve changed your password on any account that shared the same password.) There’s been a file circulating around the Internet that contains the email address, encrypted password, and unencrypted password hint for all these accounts. It’s not too hard to find.
The first interesting thing we learned from this file is that Adobe didn’t salt and hash their passwords before storing. Instead, they used a well-known symmetric encryption algorithm (3DES, ECB-mode) with the same secret key for every account. Even without knowing the secret key, it’s not hard to recover plaintext passwords with high confidence using basic statistics. Simple example: The encrypted password that appears most often in the dataset is probably going to decipher to “123456” or “password”. For this particular dataset, knowing that alone gives you the password for 2+ million accounts. (I’ll explain how you can avoid statistical attacks like this one by salting/hashing in a footnote below.)
The other interesting part is the password hints. A staggering number of people have password hints that are literally, “pwd is 123456”, which helps confirm some of the password guesses that we can make by statistical analysis. My friend Nick Semenkovich posted a sanitized version of the full user dataset (.gz, 1.1G) with emails redacted, which I filtered into a much shorter list of 8262 lines-that-might-contain-the-actual-plaintext-password using grep -Ei ‘\s+(password|pwd?)\s*(is|==?|:)’.
If you take a look at the list, you’ll see an astonishing number of password hints that either seem to give the actual password or say something like, “Password is the same as for Gmail.” The latter is especially bad because if your password is fairly common, I can probably figure it out from statistical analysis and then login to your email account.
Essentially, this is a situation where if EITHER Adobe engineers implemented secure password and password hint obfuscation OR every Adobe user created perfectly random passwords and secure password hints (== probably no hint at all), things would be mostly okay despite the database breach.
I don’t want to be presumptuous about why Adobe didn’t follow recommended password storage protocols, but it seems that the twofold lesson here is that engineers need to have a realistic user model and users need to have less trust in engineers to protect them.
====
A quick primer on salting and hashing passwords:
Hashing for password storage is a pretty magical thing. Unlike encryption (which is an invertible function once you have the secret key), usually the only way to get the input to a secure hash function (aka: the user password) from the output (aka: the password ciphertext) is to brute-force. Hash functions are at least half-magical because similar inputs get mapped to completely different outputs except by coincidence.
If all the users of your website had completely random passwords all the time, you could feel free to post the hashes of their passwords publicly as long as you trusted the hash function, because there’s no easy way to undo a secure hashing process. Something like bcrypt or scrypt with a high work factor.
The problem is that humans tend to reuse strings exactly for passwords, so if we get a database dump we can do statistical deductions and grab the nearest table of precomputed hashes for common strings. So we need adjust our user model from “people who make perfectly random passwords” to “people who might just use ‘password’.”
Then the solution is pretty simple: we just generate a random string for each user when they make their password (a “salt”) and append/prepend the salt to their password before hashing. We have to store the salt in our database alongside each user’s salted-hashed password, but that’s fine because it reveals no information about the plaintext password.
Note that you should never use the same salt for multiple users; otherwise you end up in basically the same situation as Adobe when someone gets your password database dump.
Oct 13, 2013
This is a post about fear. It’s easy to write about things that everyone says they are afraid of, but less so about nightmares that you suspect might just be your own. The latter is much more distressing and also easier to push out of the way. I’ll try to elaborate on something that has been in the back of my mind.
Last night, I went to a talk by my friend Andy titled, “Cypherpunks 2.0.” Andy thinks that there’s been two major waves of activity in the cypherpunk movement: the one that peaked in the 90s and put technologies like PGP, SSL, OTR, and Tor in the hands of ordinary people (at least in the U.S.); and the one that started this summer in response to the Snowden leaks.
Andy is hopeful. He points out that Cypherpunks 2.0 has dozens of active crypto and techno-activism mailing lists, as well as IRL meetups like Techno-Activism Third Mondays, CCC, and Cryptoparty. On the technology front, we’re watching projects like Tahoe-LAFS, CryptoCat, Whonix, and Tails become what John Gilmore referred to as the physics and mathematics that guarantees a fair society when legal systems are insufficient (as they typically are).
There was a slide in Andy’s talk that really stuck with everyone in the audience. It read:
[Cypherpunks 1.0] “Look at this utopia we can build, using cryptography!”
[Cypherpunks 2.0] “Look at this dystopia we have built, using cryptography!”
And yes, Cypherpunks 2.0 feels less like a revolution for utopia through free cryptography and more like an arms race against Orwellian governments that fundamentally disagree with us on whether privacy is a human right. Cypherpunks today don’t talk about winning, for the most part. We talk about staying above water. We say that the best we can do is to make mass surveillance both illegal and extremely difficult through maximal use of end-to-end encryption. We’re doing the best we can to prevent and protect people from the hells of targeted surveillance if they are ever so unlucky, but it’s hard to make promises when you don’t know if your adversary model is close to realistic.
Last night, I realized that every article I had read about the Snowden leaks either implicitly or explicitly suggested that we should be afraid, because the Orwellian dystopia is already here. Everyone is being watched all the time. Our crypto abilities are decades behind those of the government. Free societies cannot exist in such a state. Etc.
None of the above distresses me, though. Those of us who identify as cypherpunks or simply people who dislike surveillance are in a better spot than before. Every week, we learn a bit more about how government surveillance works, and we adjust our tactics accordingly. Pull, push, merge.
The part that I am truly, deeply, unapologetically terrified of is that we’ll step away from our laptops, take a look at American society as a whole, and find that almost nobody cares.
I’ve had this fear in some form or another for a decade. In 2006, I was 15, rather cynical, and planning to drop out of public school in inner-city Saint Louis. I wanted generational identity instead of Facebook wall posts, protests instead of biweekly third-period Home Economics. There was nothing I despised more than apathy.
That year, I purchased the first book I ever bought for myself. It was Amusing Ourselves to Death, an ever-relevant work of nonfiction written by Neil Postman in 1985. The foreword has a stunningly prophetic passage that, like a boomerang, swings out of the far blue distance and dares us to duck fast:
. . . we had forgotten that alongside Orwell’s dark vision, there was another- slightly older, slightly less well known, equally chilling: Aldous Huxley’s “Brave New World.” Contrary to common belief even among the educated, Huxley and Orwell did not prophesy the same thing. Orwell warns that we will be overcome by an externally imposed oppression. But in Huxley’s vision, no Big Brother is required to deprive people of their autonomy, maturity and history. As he saw it, people will come to love their oppression, to adore the technologies that undo their capacities to think.
Postman, in painful detail, considered the possibility that Huxley, not Orwell, was right. Nonetheless, nobody really wants to talk about Huxley. Orwellian surveillance is, in a certain light, a sexy thing to fight against. The apathy of the average person who spends 4 hours per day watching reality TV is not. For most of us, it’s much more fun to hack on Tor than to explain to a grocery store cashier why they should support free software projects that are far less usable than Dropbox.
My fear is that outside of the technological elite, convenience will perpetually win over privacy. I’m afraid that if staying alive in the war against surveillance relies on winning the war against apathy, Cypherpunks 2.0 is moving forward in the wrong direction.
Oct 12, 2013
Tonight I found a collection of stupendously precocious (lolol) poems I wrote on a trip to Memphis at age 13. Here they are, untouched, in all their prematurely cynical glory:
I’m going to Hell
I mean Memphis, in two hours
Do not raid my house.
If I don’t return
Do not mope like Charlie Brown
You’re not in my will.
I gave my pet bird
To some short college student
With lots of birdseed.
My root beer is flat
I must have left it too long
Is this relevant?
We are carpooling
With some friend of my father’s
Hope he pays for gas.
Going to find Elvis
Because Lauren told me to
Even though he’s dead.
Auditorium
The word has five sylables
I didn’t spell that right.
The smoky mountains
Because only you can stop
Those big forest fires.
At Holiday Inn
They give you little bottles
Of lousy shampoo.
Someone tell Kathy
Of the YMCA band
I can’t audition.
Chinese food is good
Especially the sushi
Wait, that’s Japanese.
They had a nurse shark
But everyone thought it was a
Mutant catfish.
Sushi bars are good
And so is the free soy sauce there
I spilled a bottle.
Graceland was real big
But the tour guides were real dumb
That’s why I got lost.
I did meet Elvis
He was at his old garden
Deep under the ground.
His airplane’s inside
Was covered in plastic wrap
Must have been itchy.
He had many suits
All colors, jeweled and sequined
Now worn by dummies.
The gift shop was cool
A nice place to be until
You saw the price tags.
I bought a milk-shake
It had lots of iced vanilla
My brain is frozen.
The hotel forgets
To give me a bed at night.
Now that is stupid.
I’d better go now
It’s been great writing these, but
The Simpsons is on.
Oct 2, 2013
I wrote a Firefox addon one afternoon in France called TabStash. It’s quite simple: you click a button to close all your tabs except the current one. You click it again to open all of them. (Chrome has a popular extension called OneTab that does this, but at the time there wasn’t a Firefox version.)
A couple nights ago, I finally got around to sending it to the Mozilla addon store. It came out yesterday and already has some downloads, to my surprise.
Anyway, you can find it at https://addons.mozilla.org/en-US/firefox/addon/tabstash/.
Oct 1, 2013
I flew back to MIT recently for the GNU 30th Anniversary Celebration and Hackathon, thanks to a generous travel scholarship from the Free Software Foundation. All I had to do was never, ever run any proprietary javascript in my browser and something something something about firstborns. Seemed like a net win.
The hackathon itself was fun. I spent most of it teaching people about privacy-enhancing tools like GnuPG and realizing that privacy-enhancing tools are intimidating, even to MIT computer science PhD students. Bad user interfaces are astonishingly powerful, and nothing cripples the human spirit like a poorly-written manpage.
I also gave a short talk to about ~30 undergrads titled, “Things you should be afraid of that you probably didn’t know about.” The alternate title was, “Useful self-preservation tactics in surveillance states.” The alternate alternate title was, “On the possibility of preserving student culture at MIT.” I admit I was trying to get more people to show up on a Friday night.
The problem was that, after an unexpected adventure in NYC the day before followed by an untimely laptop battery failure, I had barely twenty minutes to prep for the talk. So I went for a short run around the Charles River and formulated some thoughts. They went something like:
- Surveillance is bad. Do MIT undergrads care? Or are they still trying to implement metacircular evaluators in Scheme?
- DO NOT LET PEOPLE GIVE INTO CRYPTO-NIHILISM. Show them that we can only fight what we know.
- Privacy, if it actually exists, must belong to a community. Privacy that belongs to individuals is necessary but not sufficient.
- Ethical choices are painful and often ambiguous. Say you’re the CEO of a company that makes a groundbreaking app that reduces vehicle emissions by 90% in the US. In order to do so, you need to collect data on where everyone’s cars are located at all times. Then one day the government puts you in a position where your choices are to either (secretly) give them years and years of private user data or let the company shut down (and lose all your money). What do you do?
- Imagine if the MIT administration wiretapped all student communications on the Internet and forced every mailing list to contain an administrator. Imagine the student response. Now imagine the same situation at the national scale. This is a useful exercise to brainstorm realistic ways of fighting problems that seem too large and abstract for us to think about at first (ex: mass unchecked government surveillance).
To my surprise, the talk went over rather well. People asked lots of excellent questions, like what kind of tinfoil hat to buy. Phew.
Another thing that has come up a lot on this trip is the idea of having a career. As much as I feel uncomfortable about it sometimes, I can’t help but admit that the topic of What To Do In Life has been on my mind lately. The annual MIT Career Fair was a week ago, a bizarre anti-celebratory festival during the first week of classes where hundreds of companies try to recruit students by giving them free Rubix cubes. This year, one courageous sophomore wrote an opinion article in the school newspaper about how the Career Fair is useless for inspiring faith in the student population’s ability to give a fuck about problems other than making cool-but-also-profitable technology and making hella cash.
Obviously this is a thorny issue wrapped in questions of whether the author has properly normalized for her own privilege (she probably has) and if large tech companies like FB/Apple/Google are already doing the maximal amount of good for humanity that they can while remaining profitable (they probably aren’t), BUT it was still surprising that most critical comments essentially said: “Stop looking down on other people / some of us need to make a living / not all corporations are completely evil.” Multiple commenters accused the author of “entitlement”, which seems like a ridiculous term to cast as an insult (aren’t we all entitled to pursuit of happiness?).
Disliking the percentage of commenters who were unfairly bashing on the author, I wrote an uncharacteristically optimistic comment for someone who doesn’t have a consistent job:
This post was entirely justified and necessary. (Minus the fact that Quizlet probably doesn’t deserve to be on that list, as RJ pointed out.)
A number of the criticizing comments here have argued that companies like Apple and Facebook, on their way to making massive profits, ultimately spawn technologies that do good for the world; furthermore, even MIT students need to support themselves day-to-day regardless of their greater goals. But I think a salient counter-argument is that MIT grads can and absolutely must hold themselves to a higher standard than what these companies represent.
What I am implicitly saying is that (1) there are greater problems that humanity faces than how to get people to trigger certain javascript callbacks that generate ad revenue, and (2) people with the intellect and stamina to lead technological revolutions have a near-moral responsibility to solve these greater problems. The fact is that most MIT graduates can find a job and figure out a way to support themselves in most circumstances, which means they have a rare privilege among young people: the ability to take on great risks and be okay if they fail.
In practice, a dismayingly small percentage of MIT graduates use this privilege for tackling the hardest and most valuable problems of our generation. Climate change is a fine example, given that the lower limit of the time it’ll take for atmospheric methane to collapse the global economy is on the order of decades.
Even those of us who work as software engineers and tech CEO’s usually fail to address the question of whether we are making technology for a world where knowledge is free and accessible to everyone, or a world where governments and corporations can freely intrude on the private communications of every single person. Too often, we generate technology that is groundbreaking and astonishing without conscientiously addressing their potential to destroy civil liberties and strip away basic human rights. We can and must exert more pull over the ethical consequences of our innovation.
It is absolutely our moral responsibility to try to make the world we want to live in.
I really hope I didn’t make all of that up.
Sep 13, 2013
Below is an amalgamation of some posts that I made recently on a popular microblogging platform:
========
I’ve been reading a lot today about what I believe is a super-likely NSA backdoor into modern cryptosystems.
There are these things called elliptic curves that are getting used more and more for key generation in cryptography, especially in forward-secrecy-enabled SSL (which is the EFF-recommended way to secure web traffic). The problem is that the choice of parameters for the elliptic curves most used in practice are set by NIST, and we know for sure that the NSA has some influence on NIST standards.
In 2006, NIST published an algorithm for elliptic-curve based random number generation that was shown to be easily breakable but ONLY by whoever chose the elliptic curve parameters. Luckily this algorithm was crazy slow so nobody used it, even though it was the (only?) NIST-recommended way of generating random bits with elliptic curves.
But it turns out there are some relatively-obscure papers that suggest that you can gain a decent cryptographic advantage by picking the elliptic curve parameters! [Edit: It was later pointed out to me that this particular attack is not close to anything the NSA could be doing right now, for various reasons. It is of course unclear whether they have knowledge of other elliptic curve parameter-based attacks that are not in the academic literature.]
This is terrifying, because the elliptic curve parameters chosen for relatively-mysterious reasons by NIST (probably via NSA) are used by Google, OpenSSL, and any RFC-compliant implementation of elliptic curves in OpenPGP (gnupg-ecc, for instance).
==========
Some people might be wondering if they can trust companies who issue statements that their closed-source software products don’t contain NSA backdoors (Microsoft, Google, Apple, etc.). Here is an example of why not.
It has been known since 2006 that Dual EC DRBG (a NIST-standardized random bit generation algorithm) has a major vulnerability that makes no sense except as an NSA backdoor. Essentially, the algorithm contains some constant parameters that are left unexplained; some researchers then showed that whoever determined these parameters could easily predict the output of the algorithm if they had access to a special set of secret numbers (analogous to an RSA private key). This is a beautiful design for a crytographic backdoor, because the secret numbers are difficult to find except by the person who set the constant parameters in the algorithm.
Despite being slower than other random bit generators, Dual EC DRBG is implemented in a bunch of software products by major companies like RSA Security, Microsoft, Cisco, BlackBerry, McAfee, Certicom, and Samsung. For a full list, see: http://csrc.nist.gov/groups/STM/cavp/documents/drbg/drbgval.html
Most of these products are closed-source, so you can’t check whether your encryption keys are being generated with Dual EC DRBG.
This is a pretty strong argument that secure software is necessarily open source software.
========
Additional citations:
Bruce Schneier on the 2006 backdoor discovery in Dual_EC_DRBG: https://www.schneier.com/…/2007/11/the_strange_sto.html
Google’s blog post announcing SSL w/ forward secrecy, specifically mentioning that they use the P-256 curve: https://www.imperialviolet.org/2011/11/22/forwardsecret.html
Wiki section on NIST-recommended curves: https://en.wikipedia.org/wiki/Elliptic_curve_cryptography…
RFC section stating that P-256 is REQUIRED for ecc in openpgp: http://tools.ietf.org/html/rfc6637#section-12.1
Description of elliptic curve usage in OpenSSL: http://wiki.openssl.org/…/Elliptic_Curve_Cryptography
Presentation on security dangers of NIST curves: http://cr.yp.to/…/slides-dan+tanja-20130531-4×3.pdf
NSA page recommending you use elliptic curves lol: http://www.nsa.gov/business/programs/elliptic_curve.shtml
========
UPDATE (9/23/13): RSA security has issued an advisory to stop using some of their products where DUAL_EC_DRBG is the default random number generator (http://arstechnica.com/security/2013/09/stop-using-nsa-influence-code-in-our-product-rsa-tells-customers/). Matthew Green also made an excellent blog post about this topic over at http://blog.cryptographyengineering.com/2013/09/the-many-flaws-of-dualecdrbg.html.
Sep 2, 2013
Working on HTTPS Everywhere, an open source project with dozens of contributors, has sharpened my git vocabulary immensely. I figured I’d list a few lesser-known commands that I like:
- git log _-pretty=oneline -n –abbrev-commit -G_: This shows the latest commits in oneline format with shortened commit hashes that added or removed lines matching . The git pickaxe options (-S, -G) are super useful for searching git commit contents instead of just the commit messages.
- git checkout <path/to/file>; git reset; git add -p; git commit: This is almost always less preferable to git cherry-pick, but it is useful when you want only certain hunks of commits to certain files in . git checkout copies the file from the other branch into the current branch and stages the changes for commit. git reset unstages them so we can select the parts we want to add to our branch on a hunk-by-hunk basis using git add -p. Unfortunately this doesn’t preserve authorship of the changes from .
- git update hooks: We decided that it would be great if the HTTPS Everywhere git server could automatically reject commits that broke the build. It turns out that this is possible using a server-side git update hook, which runs just before updating the refs on the git server. The strategy is to create a temporary copy of the remote with the newly pushed changes, do a test build, and reject the changes if the build fails. See here for an example of this in HTTPS Everywhere adapted from a Stack Overflow answer.
More to come!
Jul 27, 2013
Quick update to mention that a new version of the browser extension I’ve been helping with this summer has just been released!
This release was spurred by the impending arrival of Firefox 23, which notably has Mixed Active Content Blocking enabled by default. In summary, this means that scripts loaded via HTTP on an otherwise-HTTPS site will be blocked automatically for security reasons. Although this is good news in general, it would have suddenly caused HTTPS Everywhere to become way less usable.
Micah at the EFF did tons of work on this one to make sure that mixed content rules in HTTPS Everywhere wouldn’t break a massive number of websites for FF23 users, while I implemented the UI to alert users to the fact that they would have to re-input any custom preferences once they updated to 3.3 (unfortunately). I also ended up fixing a previously-undiscovered bug along the way that prevented the HTTPS Everywhere tool-tip from showing up when users install the extension.
It’s kind of sad that the tool-tip didn’t show up for most people before. Did you know that you can disable HTTPS Everywhere rules by clicking on the toolbar icon? This is very handy when certain rules cause a site to break for some reason.
Anyway, happy upgrading!
